Introduction
There’s a certain joy to scribbling down a note, whether in a physical notebook or a digital notes app. We can write down information in whatever messy format we want, with no formal ceremony.

Examples of “micronotes”, from our personal notes, and from the research paper Understanding the Micronote Lifecycle: Improving Mobile Support for Informal Note Taking
However, these days, we increasingly use purpose-built software applications to manage personal information like recipes, workouts, budgets, and schedules. These apps provide all sorts of useful computational benefits—calculating workout statistics, budget trends, and more—but this power comes at a cost: apps lose much of the freedom of a note.
All the information we enter must now fit the categories and taxonomies of the application. And if the tiniest of features is missing from the app, we usually have no choice but to file feedback and hope the developers make a change.
We think a promising strategy for bridging the gap between docs and apps is gradual enrichment: allowing users to record information in natural, messy ways, and then slowly adding formal structure and computational behavior only as needed.
One inspiration for gradual enrichment is spreadsheets. In a spreadsheet, a user can start writing down data in a freeform grid, without committing to any particular structure. They can then write formulas that run computations on information, if and when it’s useful to do so. Eventually, after lots of iterations, they might arrive at a highly complex software application, but one grown organically from their data and unique needs. At every point along the way, the artifact remained useful and grounded in real needs.
In this essay, we explore how it might work to apply this kind of gradual enrichment to text documents. People often jot down freeform text notes—recipes, schedules, workouts, chores, and more—using apps like Apple Notes and Notion. These notes contain meaningful information, like quantities in a recipe or weights in a workout log, that can serve as the basis for useful computations. How might we enable people to gradually turn these text documents into custom pieces of software?
Potluck is a research prototype that demonstrates a workflow for gradually turning text documents into interactive software. It has three parts:
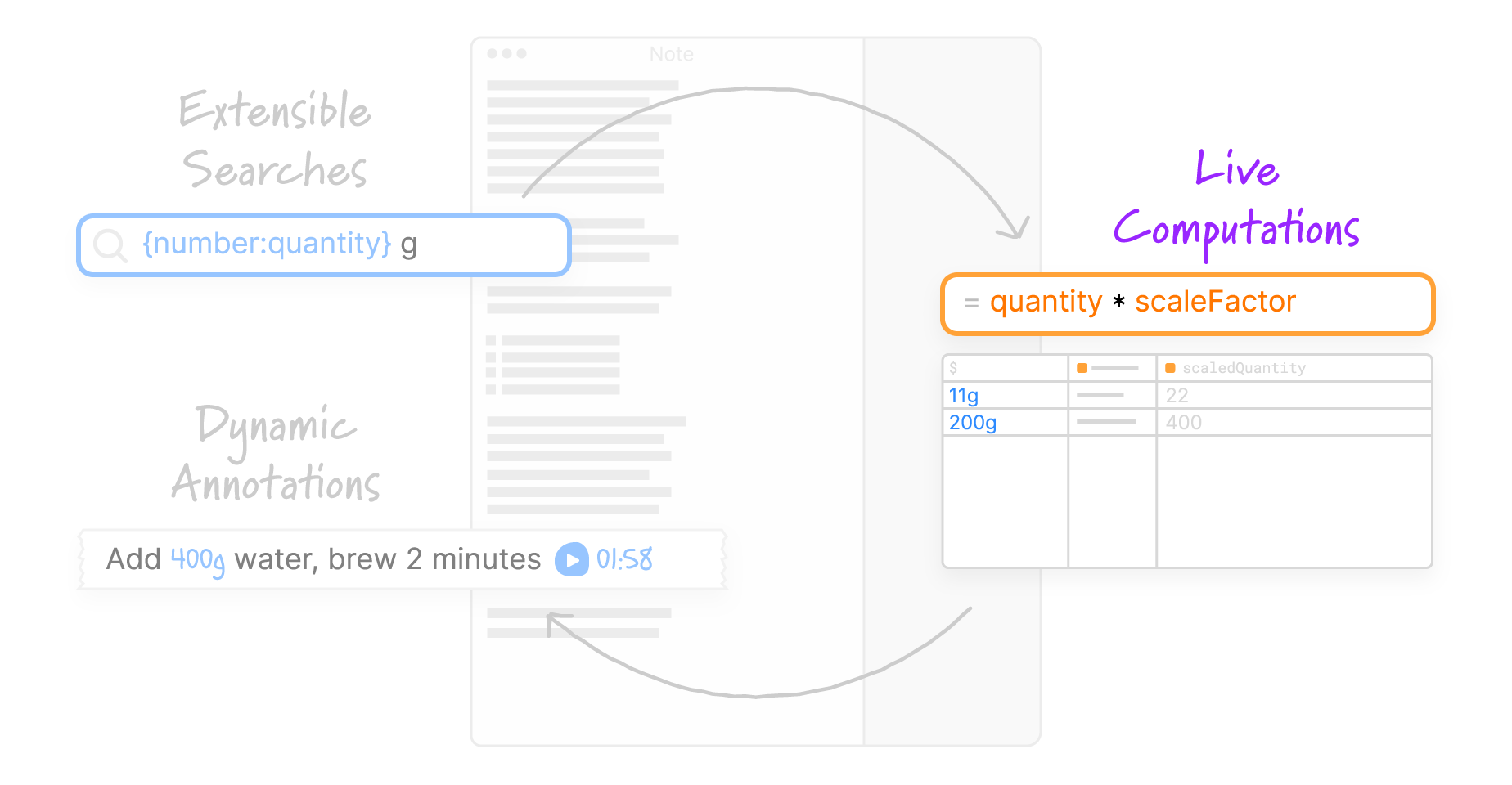
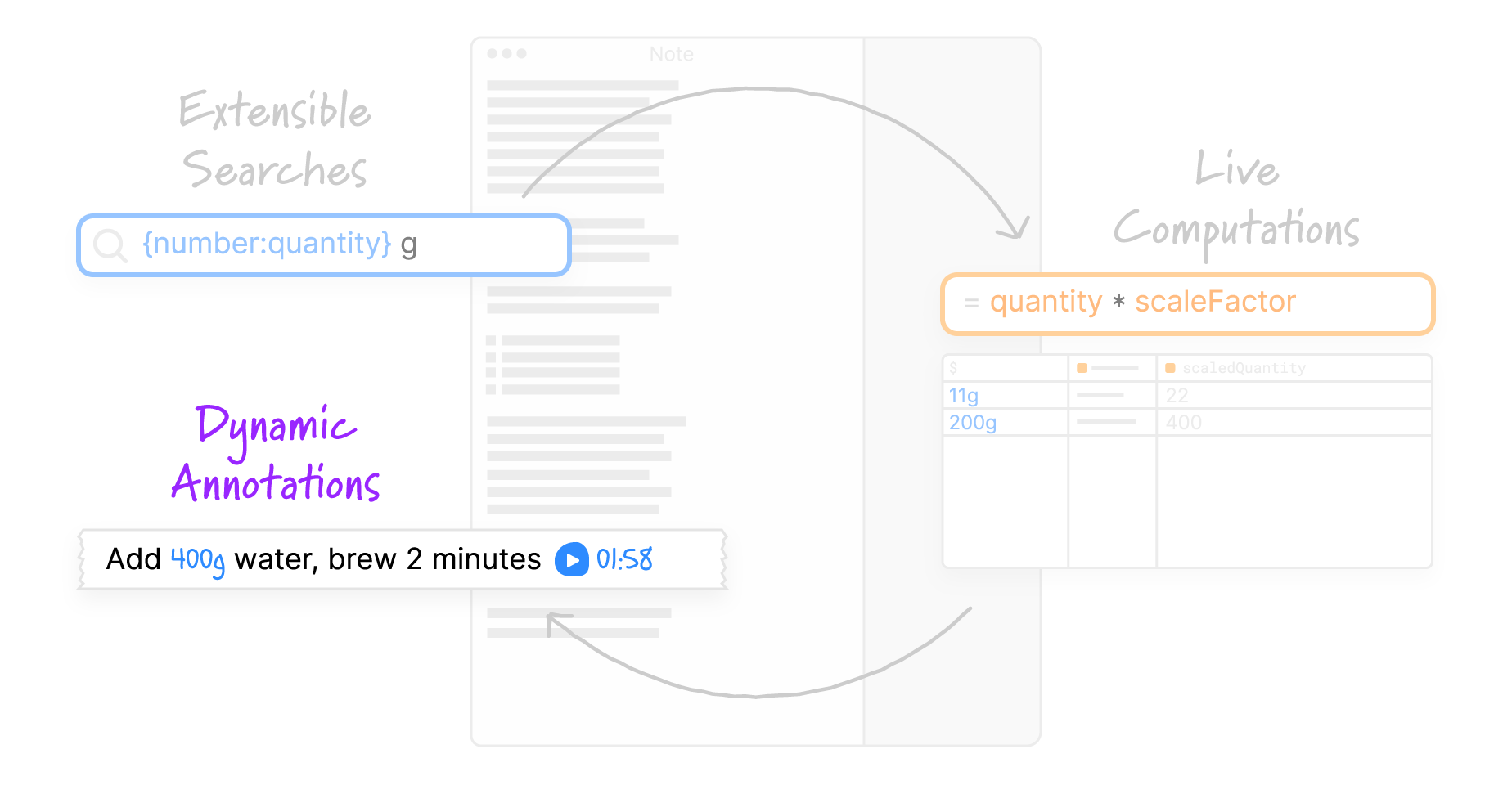
- Extensible searches
Users can define searches: custom patterns that detect data within the text of a note. Searches are defined in a compositional pattern language which allows reusing patterns that others have written. - Live computations
Once data is extracted from the text document, users can write formulas that compute new values based on the extracted data. Formulas are written using JavaScript, in a live programming environment that resembles a spreadsheet. - Dynamic annotations
Computed values can be displayed in the original text document as annotations. Potluck provides a few annotation types that can insert new text, cover up or restyle the original text, or even inject interactive widgets.
Together, these ideas form a loop. By treating text as both a source of information and a substrate for hosting a user interface, we can turn a text document into an interactive application.
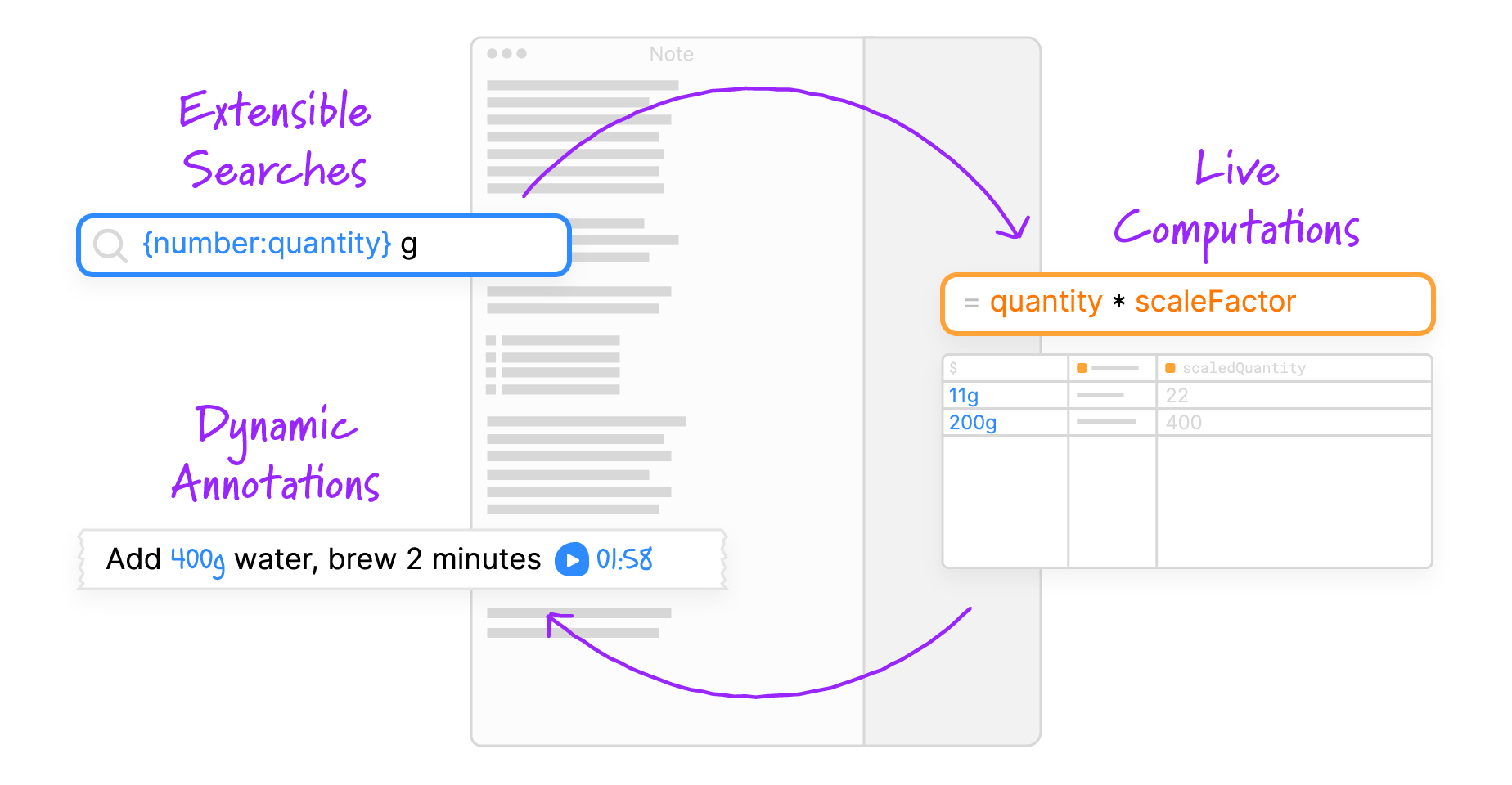
The Potluck interaction model forms a loop: extract data from text, compute with that data, and then display results back in the text.
Let’s see an example of how it feels to use a simple Potluck document. Below is a simple recipe for making coffee, which includes an interactive slider that can scale up the number of servings. The demo starts out as a video, but if you click on iton the button below it you can interact with a live version.
💡 Try it
- Move the slider above "Servings", and watch the numbers change.
- Type in a new instruction, "Add 5g sugar", and see the quantity get scaled.
The interactive and computational behavior of this document was constructed within Potluck itself. Later we’ll explain the details of how it was made; for now it’s sufficient to know that we’ve 1) constructed a search that finds the quantities of coffee and water, 2) run a computation that multiplies those quantities, and then 3) set up some annotations to overlay the scaled quantities over the original ones.
We’ve found that many different kinds of software can be built in Potluck. We’ve used it to build tools for tracking household chores, managing a cash register, organizing a meeting agenda, tracking workouts, splitting a bill, and planning a trip.
Below are a few examples. You can try editing the text and interacting with the documents to see how they work.
A note to keep track of when we last watered each of our house plants.
Dates that are overdue for watering are highlighted in red.
💡 Try it: Edit one of the dates to be today's date, or just click the 🚿 button.
A workshop agenda. Each line has a duration, and the start/end times are computed.
If you use the arrow keys to move the cursor to a line beginning, you'll see the duration.
💡 Try it: Add a new line to the bottom of the agenda: "45 minutes Conclusion"
A cash register where each item for sale is represented as an emoji
💡 Try it: Add a new sale by entering "☕️", "🍰" or "🧁" in a new line under "## Sales"
A note for timekeeping. With the timer button users can track their time and the total duration is computed automatically.
💡 Try it: Track some time by clicking on start and then stop again.
We’ve found that starting with freeform documents promotes a wide variety of use cases. Existing notes can serve as inspiration, rather than trying to build applications from a blank slate. We’ve also found that barebones text-based UIs are sufficient for many personal use cases, without the need for a full layout design.
The idea of gradually enhancing a document into a software application is not new. It’s related to document-based productivity tools like Coda, Notion, Roam, and Logseq, as well as research systems including Documents as User Interfaces, Webstrates, and Smalltalk. What, then, are the contributions of this work? Potluck extends in two directions less explored by prior work:
- Using freeform text data as a source of information for computations. Many tools only allow users to compute with data that's been put into a specific structured format. In Potluck, we encourage people to write data in freeform text, and define searches to parse structure from the text.
- Using text annotations to power an interactive interface. Even in tools that combine documents and computation, there's often some separation between editable text and computational results. In Potluck, we deeply entangle interactive elements with the user's text, by providing dynamic annotations that can overlay or restyle the original document. The effect is to treat the text itself as a place to host UI.
It’s worth noting there are still some important limitations and open questions that we haven’t yet resolved. While we care about enabling non-programmers, and have made some design decisions with them in mind, our current prototype does expect the user to have basic knowledge of JavaScript, and our test users have mostly been skilled programmers. We’re also not yet sure exactly where the limits of this model are—what kinds of apps are possible and desirable to build in this style?
If you’re a reader who builds software applications, we hope this work encourages you to consider the benefits of freeform data formats and deferring structured formalism. If you’re interested in more abstract ideas about how software could be organized, we hope this work demonstrates the value of gradual enrichment, and hints at the potential of systems that enable users to build personal software on top of their existing freeform text data.
Motivation: bridging apps and documents
Applications are of the most familiar metaphors in using a computer today, so it might seem strange to question their value. But in this section we’ll argue that, when examined closely enough, the application model imposes serious rigidity on users. In contrast, we’ll show that documents have some intriguing benefits due to their more freeform nature, but have their own drawbacks.
The rigidity of apps
Let’s examine some of the kinds of rigidity that applications impose on users. To ground our analysis, we’ll use some concrete examples from Paprika, a popular recipe management app that provides useful features like scaling ingredients and setting timers.
One problem with apps is that they have predefined feature sets that the creators deemed appropriate for the goal. It’s impossible to make a small tweak, or even remove an unwanted feature, unless the creator of the app has explicitly allowed for the change. Each app has a (often narrow) domain that it considers in scope, requiring us to learn to use many independent apps that don’t compose together well. In short, apps enact rigid boundaries between tasks, and define rigid solutions within those boundaries.
As an example, consider the sidebar in the Paprika recipes app, which includes many extra features beyond recipes: grocery shopping, pantry management, meal planning, and a feature for assembling “menus” out of recipes. On the one hand, this feature set is very broad: the extra sidebar items may be unnecessary for many users, but there’s no way to remove them. On the other hand, the application still has a narrow focus, since it siloes away cooking as a separate domain from the rest of life. In the analog world, it’s natural to combine a grocery shopping list with other chores for the day, but there’s no way to easily integrate a Paprika shopping list with other notes in another app.
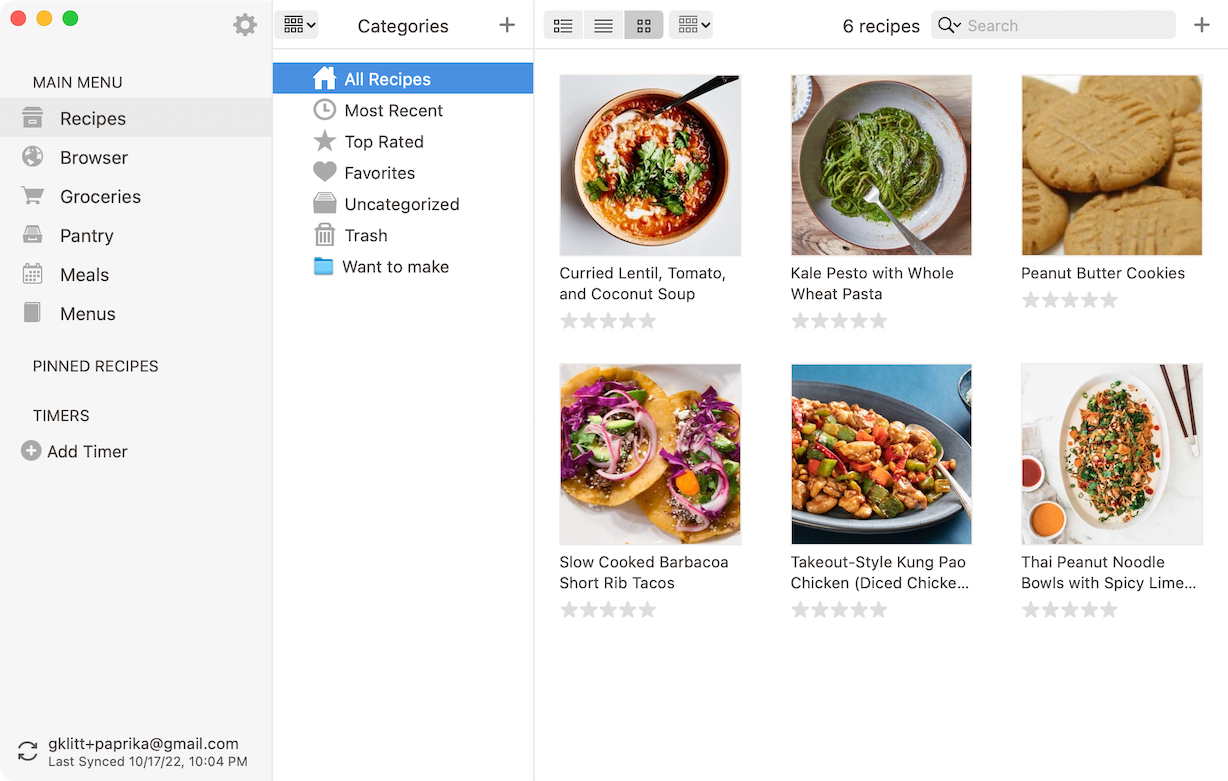
Beyond the core recipe functionality, Paprika’s sidebar has extra features for Groceries, Pantry, Meals, and Menus
There’s another important dimension of inflexibility: apps create rigid data schemas that define the kinds of information we can record within them. We can fill out the available form fields, but we can’t add new fields or scribble in the margins. Structured data inputs struggle with ambiguity—when faced with a list of radio buttons, there’s no way we can select two options, like we might have done on a paper form.
Here’s an example of this schema rigidity in Paprika: every recipe must list the ingredients in a separate section from the directions. This means that people can’t write recipes by simply mentioning the ingredient quantities directly within the directions. Also, when the recipe is scaled up, the multiplier only applies within the officially designated ingredients section, and doesn’t affect any quantities shown within the directions.
As another example of schema rigidity, when constructing a meal plan, you can only add a recipe in a specific slot for some date. There’s no way to ambiguously assign a recipe to either Tuesday or Wednesday, which would be natural to do in a paper notebook.
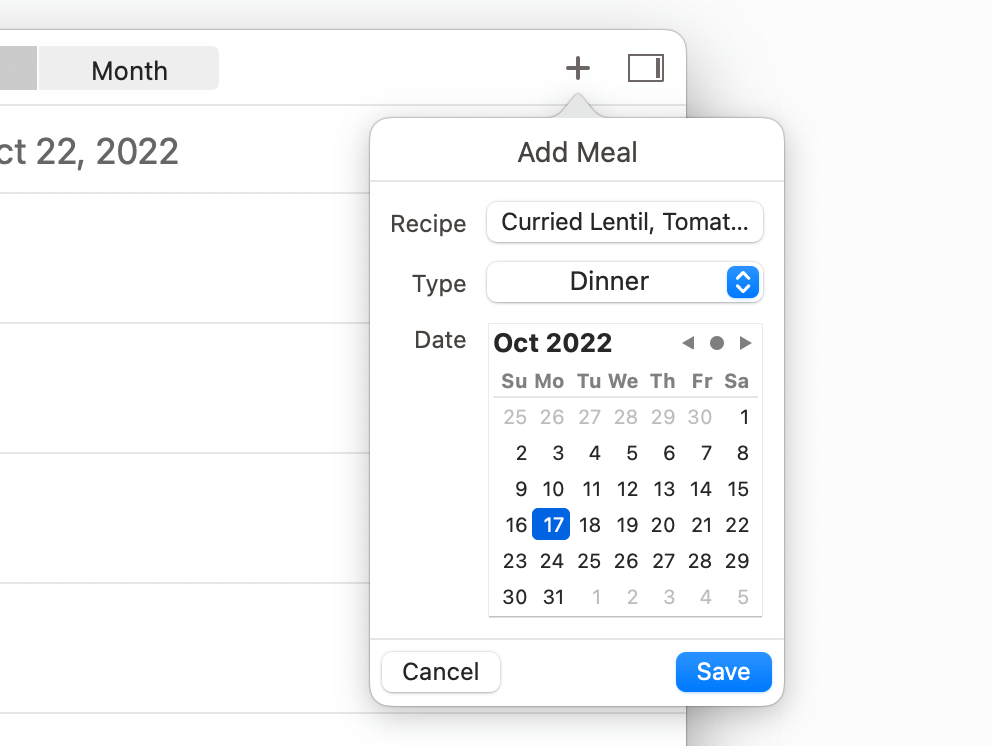
Each meal plan entry in Paprika must be assigned to a specific date on the calendar, with no room for ambiguity.
The overall effect is one of limited agency—once a user has picked the best available app, their choices end there. People aren’t encouraged to think about little further changes they might want to make, or naturally make tweaks as they go; instead, they just adapt their behavior to whatever the app encourages.
The flexibility of documents
It’s striking to contrast the rigidity of a recipe app with the natural ways that people use analog tools to manage recipes. They maintain boxes or binders of favorite recipes and hand them down as treasured family heirlooms. They write in physical cookbooks to leave their own annotations. On one sheet of scrap paper, someone can write a fuzzy sketch of a meal plan for the week, a grocery list, and some notes about other ongoing todos. Because paper is an inherently permissive medium, there’s no need to adhere to preset rules.

Physical cookbooks support easy manual annotations. Even the food stains provide a kind of Read Wear.
In the digital world, we find a close analogue to this kind of flexibility in text and multimedia documents, where we can write whatever we want. Documents have a couple key advantages relative to applications.
First, documents are useful for all kinds of tasks. A note can capture any kind of information, without needing to worry about what bucket it fits in. This generality makes for more versatile tools—there’s a common set of conventions that people are familiar with for editing text, and they’re implemented to a high degree of quality in many editors and libraries because text is such a versatile data format.
Text documents are a single versatile medium for recording all kinds of information.
Also, documents don’t enforce a schema. Text doesn’t enforce rigid schemas on what we can write, so we can work in a medium closer to how we think instead of conforming to an external system. It feels entirely natural to come up with a personal way of writing down todos or workout logs in a text note, because the medium is so flexible.
However, there’s a tradeoff: documents are static. However, documents lose the convenient computational features of an application, like automatically scaling ingredients, setting timers, or tracking nutrition statistics. This isn’t just a lack of engineering effort—there’s a fundamental challenge, which is that the data hasn’t been entered in a consistent format that the computer can reliably understand.
Gradual enrichment
We’ve seen that applications and documents each have their own advantages. How might we get the best of both worlds?
We think an appealing approach is to enable people to gradually enrich text documents. A user can start with a text document, and as they work with it, they can add bits of structure and computational behavior as needed. This process should be incremental, so that the document remains useful at every step along the way, and there’s never any unnecessary work up front.
Notably, this process can’t avoid the need to teach the computer how to interpret meaning from freeform data. The point is to defer this process until it’s absolutely needed. It’s okay to end up with structured schemas when we need them to support computational features, but when they’re not necessary, text is a perfectly adequate representation for humans to interact with.
Prior art
Many others have explored tools for mixing documents and interactive functionality. Here are a few projects we took inspiration from.
Text documents as user interfaces
A key part of the Potluck interaction model is using a text document itself as an interactive interface, by showing computed values and interactive widgets in the text.
This idea has been explored at least as far back as 1991, in Eric Bier and Ken Pier’s work on Documents as User Interfaces at Xerox PARC. They demonstrated that if we treat specific segments of text as clickable buttons, then we can arrange them in a UI by simply moving the text to the appropriate place in the flow of the document.
Arranging clickable buttons in the flow of a text document, from Bier and Pier’s Documents as User Interfaces
Modern commercial tools like Coda and Notion have also explored intertwining text and computation. Coda’s goal is particularly close to ours: allowing users to gradually enrich documents into apps, including by embedding interactive widgets and computational results in documents. However, there’s a key difference in the model: in Coda, computations run on data that stored in structured tables with defined schemas, whereas in Potluck, computations run on data interpreted from freeform text. Later we’ll address some of the tradeoffs between these approaches.
Coda supports enriching text documents with interactive computation
Plaintext knowledge management tools like Emacs Org Mode, Obsidian, Logseq, and TaskTXT allow users to write plaintext files in a specific syntax that supports dyamic functionality, such as extracting todos and surfacing relationships between entities. These tools share Potluck’s goal of building on top of the familiar and portable format of plain text, and many of them also have robust ecosystems of user-authored plugins which can extend the tools to more domains and tasks. However, these tools also tend to come with some degree of built-in, opinionated syntax and features, and writing plugins often requires leaving the tool and applying expert programming skills. Potluck places a greater emphasis on allowing end-users to define their own syntax and features, and aims to apply to a broader set of domains.
Another inspiration is Bret Victor’s reactive documents, which integrate a spreadsheet-like model into text. This allows a reader to interactively change the assumptions in a written explanation and see the consequences of those changes in realtime. While Potluck has a slightly different goal—building personal tools, rather than writing explanations for other people—we share the principle of combining the explanatory power of natural language and the dynamism of computation in a single medium.
A reactive document by Bret Victor, explaining a tax policy change
Data detectors
In their 1998 paper Collaborative, Programmable Intelligent Agents, the Apple researchers Bonnie Nardi, James Miller, and David Wright describe data detectors: intelligent pattern recognizers built into the operating system which can detect structured data like phone numbers and street addresses contained within everyday unstructured documents, and then allow the user to take actions on that structured data. This idea was productized and lives on to this day in MacOS and iOS, although without the user extensibility envisioned by the original paper.
We find data detectors promising because they allow people to represent information on their own terms. However, today data detectors are more of a minor convenience than a core metaphor in the OS. We think the reason is that the interaction model around data detectors is limited: all a user can do is manually click on a detected value and take a single action. There’s no ability to perform more sophisticated computations with the detected data, or to automatically show annotations on detected data.
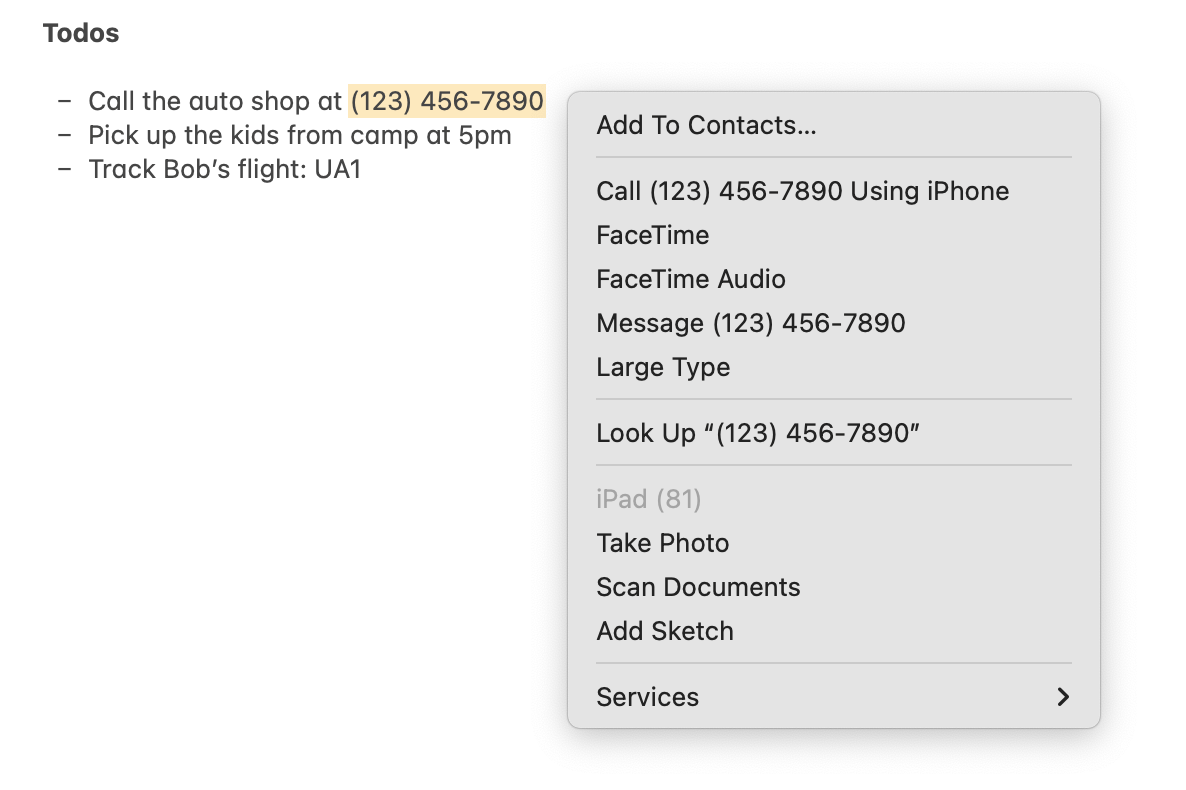
A data detector in macOS enables right-clicking on a phone number to add it to contacts or make a phone call.
Feedback loop
In order for a data detector to feel good to use in an interactive setting, it’s critical that the system can provide immediate feedback as a user types and help them develop consistent expectations for how the system will interpret their text.
One inspiration was Fantastical, which parses a natural language description into a structured calendar event. It shows instant visual feedback, and is also fairly predictable—even though the input feels freeform, the parser acts consistently enough that it’s possible to learn how to reliably write well-parsed inputs. Fantastical even publishes recommended guidelines for how to type events to help out the parser.
Fantastical provides live feedback as it parses natural language
Another example of a fast predictable parser is Soulver, a “notepad calculator” app that instantly performs math computations over a notepad with flexible text input. For example, in the video below we try typing a currency conversion, discover that the parser didn’t understand our original text description, and then adjust it on the fly to get the computation to work.
Soulver’s fast feedback allows for instant iteration
In our experience, these kinds of tools feel nice to use because they strike a good balance between natural language and formal syntax. They allow the user to type naturally, but they don’t aim to accurately interpret everything someone could possibly write. There’s a feedback loop where the user adjusts their input in response to the machine.
Extensibility
People should have the ability to encode their own knowledge and personal micro-syntax into their tools. However, defining abstract patterns over plain text can be difficult even for skilled programmers; regular expressions are notoriously hard to use. We need ergonomic tools for defining patterns.
One category of approaches is to develop better languages. For example, LAPIS, by Rob Miller, developed a set of tools for specifying and extracting patterns from text by composing together existing patterns, including a friendly syntax that resembles natural language. Another route is programming by example (PBE): letting users provide concrete examples to specify a more general pattern. This technique has been explored by many systems, including the Flash Fill system deployed in Microsoft Excel, as well as LAPIS. There are also some interesting hybrid interaction models between PBE and code editing—in User Interaction Models for Disambiguation in Programming by Example, Mayer et al. use PBE to generate candidate programs, but also let users directly edit the resulting programs.
In the next section, we explore how our Potluck tool embodies these ideas of fast, predictable, and extensible data detectors.
Potluck: an environment for dynamic documents

A coffee recipe with handwritten annotations
Potluck is a research prototype we built to explore the idea of gradually enriching text documents into interactive application. Our goal was to design a concrete model for gradual enrichment, and then to evaluate that model by using it to build personal tools.
To understand the core ideas in our prototype, let’s see how someone could use it to build the coffee recipe shown at the beginning of this essay. As a reminder, here’s the final note we’ll end up with. It contains a slider that scales the recipe quantities, and an interactive timer to keep track of the brew time.
These aren’t particularly interesting features in and of themselves; they’re common features found in recipe apps. The important point is that in Potluck, a user can build them from scratch on top of a text note without leaving the tool, and then keep customizing and extending the tool for their needs.
Extracting data with searches
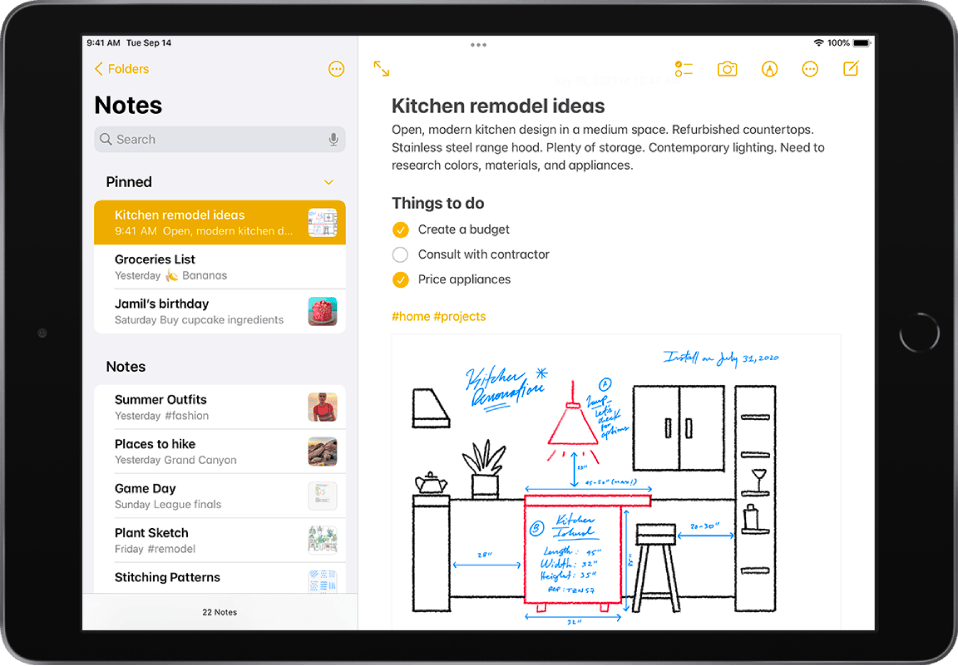
Potluck starts out looking like a familiar note-taking application; there is a list of notes to the left, an editable text area with the note’s content in the center, and a search panel to the right.
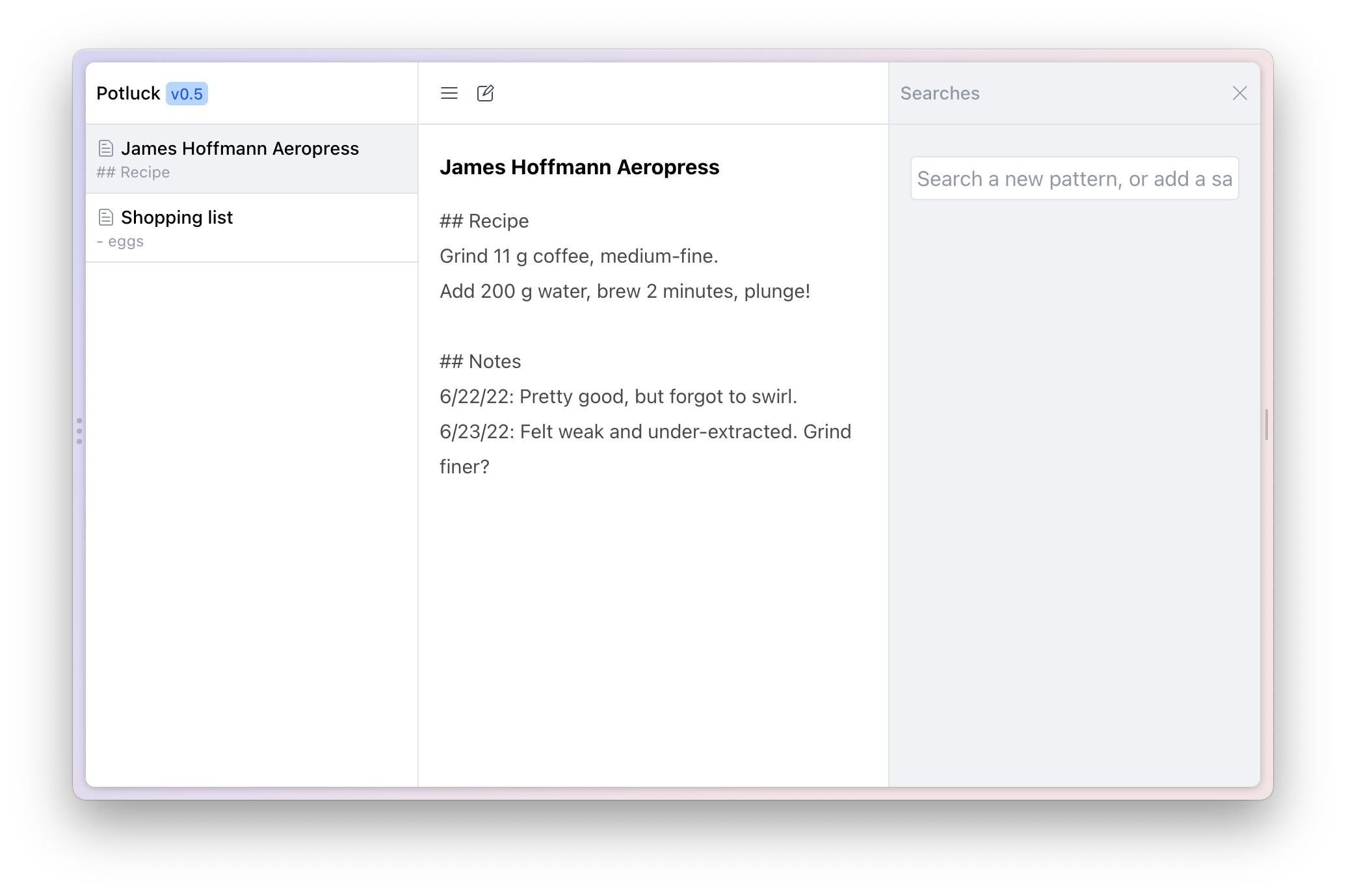
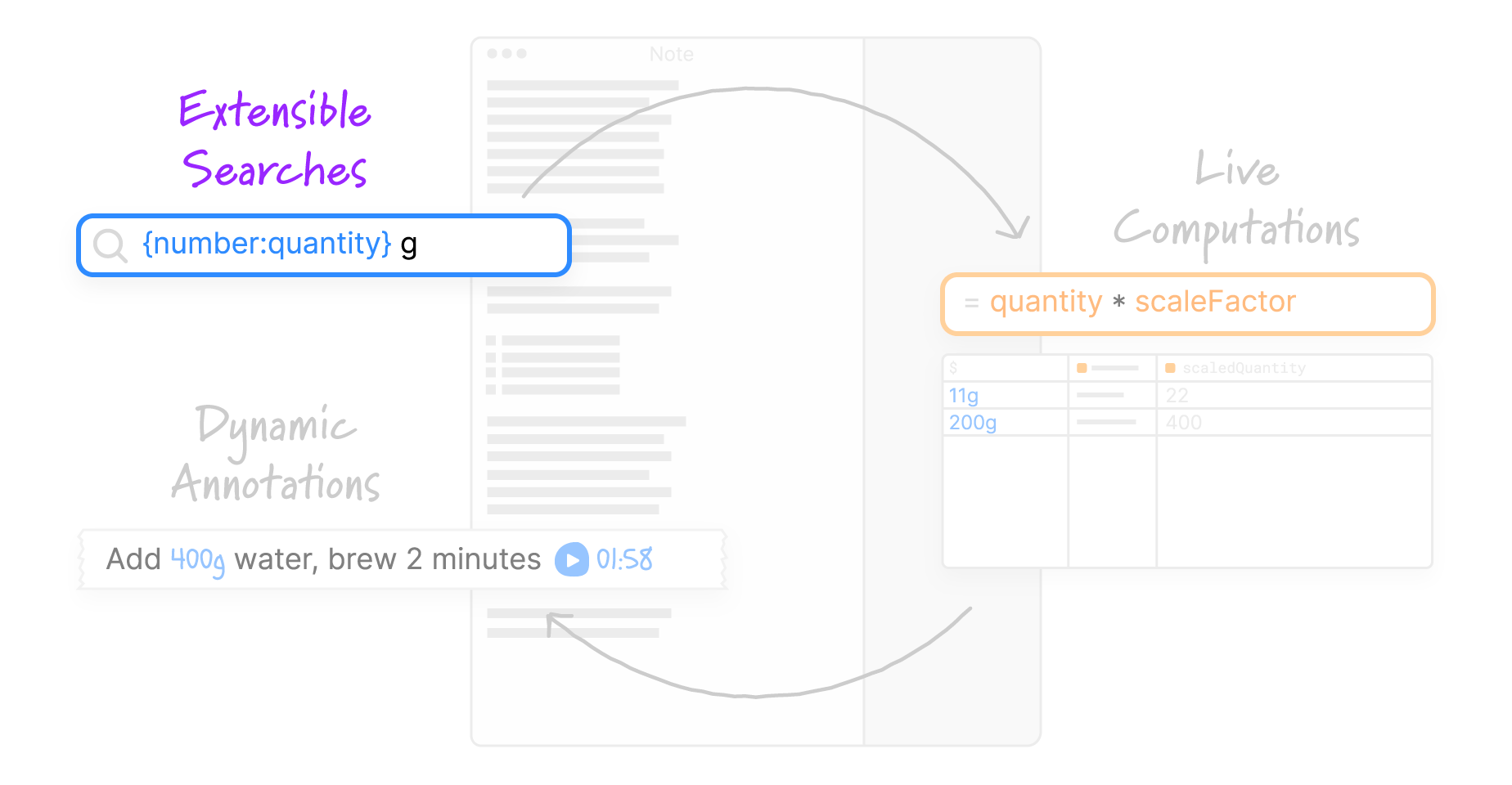
The first step towards scaling our ingredient quantities is to help the system recognize those values as structured information embedded within the recipe text. It’s important that users can define flexible patterns that can accommodate messy real world data, but also that users have control over the patterns they define, and can develop consistent expectations about how they behave.
Potluck allows users to define patterns that are recognized within a text document. Patterns are created with a search interaction. Users are already familiar with searching for content in a word processor or web browser, so it’s a natural on-ramp to creating live data detectors.
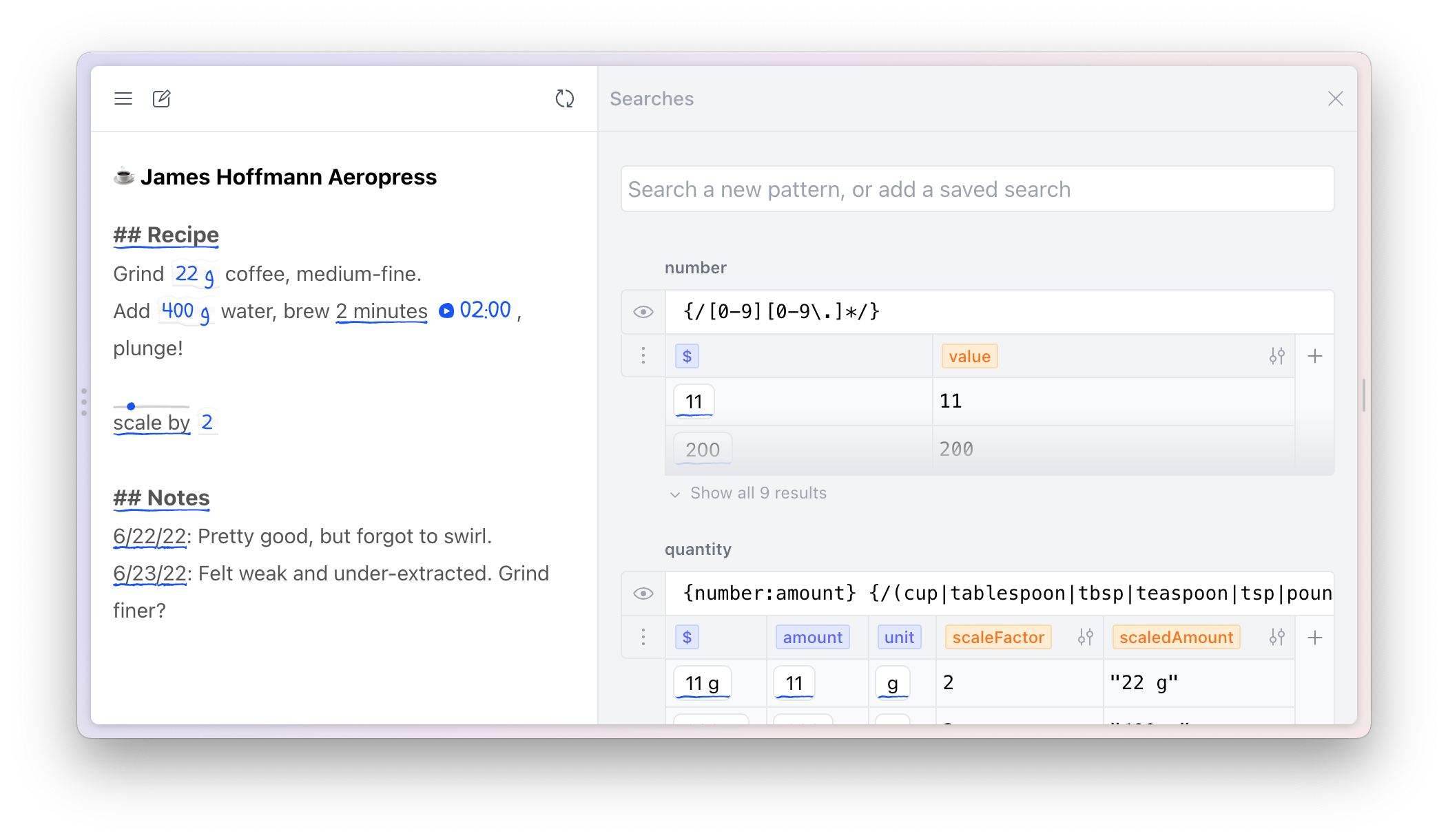
As an easy start, the user can search for a string literal: 11 g, the quantity of coffee in our recipe. The search result appears in a table in the search panel, and is also underlined in the text note itself. Searches run continuously against the note’s content, so the results update as we update the text note:
Creating a live search and seeing it respond to the updating text
Of course, a string literal is usually too specific to find all the data the user wants—in this recipe, the search has detected the quantity of coffee, but not yet the quantity of water. The search needs to be generalized to find any number followed by the g symbol. In Potluck, the user can do this by rewriting their search from 11 g to {number} g. This works because Potluck searches can reference other existing searches, by putting the name of an existing search inside of curly braces. Potluck comes with many simple patterns built in, including numbers, dates, and phone numbers.
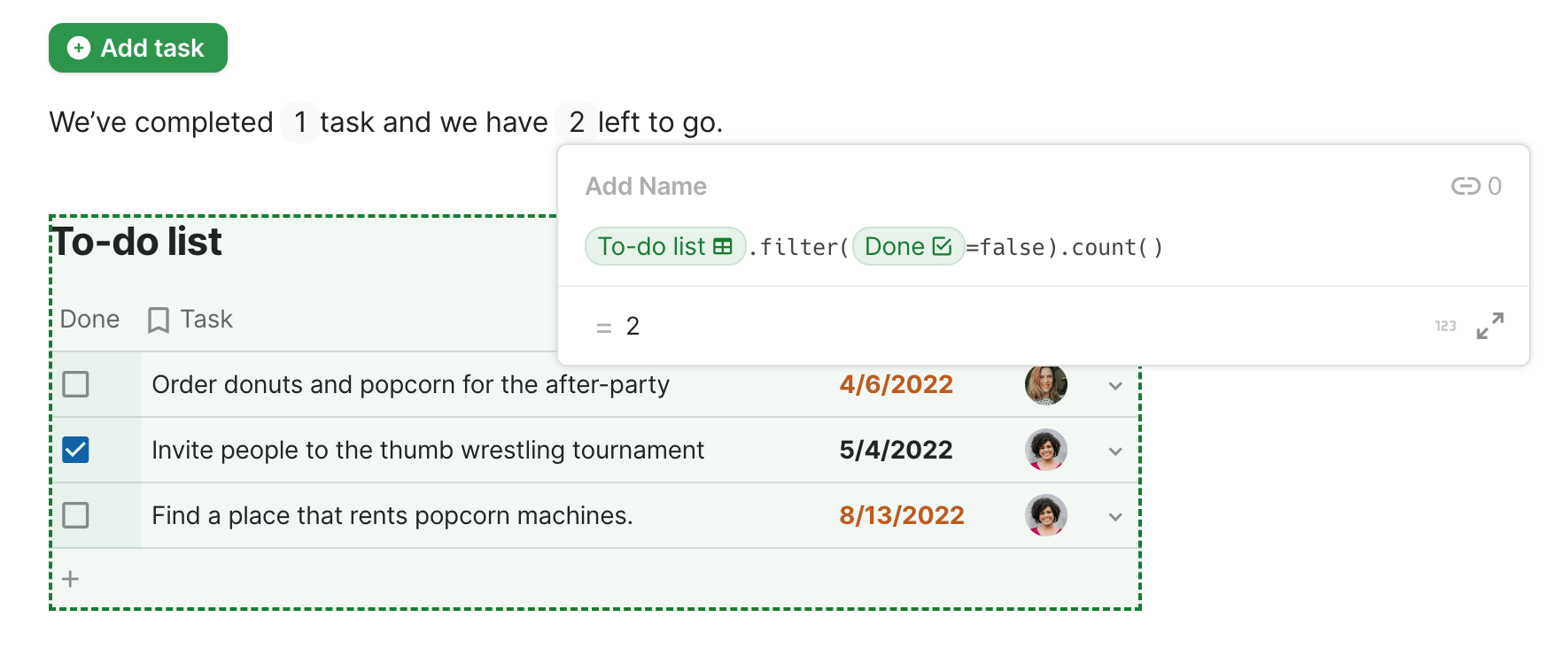
Later on, the user will want to do arithmetic using only the number and not the unit, so they can also extract the number using a named capture group. If they edit the search to say {number:amount} g, the table of results will automatically show a column that just contains the amount:
Extracting the number with a built-in pattern and named capture group
For more advanced patterns, the language also supports arbitrary regular expressions. The user could have generalized their search to support other units besides grams, by changing the unit part of the search to use a regular expression: {/g|kg|ml/:unit}. However, regular expressions can be confusing to read and write, so we generally encourage encapsulating them inside of reusable named searches. For example, the built-in number search is internally implemented with a regular expression, but the user doesn’t need to see that implementation detail.
Running live computations
Now that the quantities have been found in the text, the user needs to multiply them by some scaling factor. They can do this by creating computed properties that contain small JavaScript expressions.
In this case, the user adds a computed property called scaledQuantity that is the result of multiplying the quantity by a scale factor. For now, they want to make 2 cups of coffee, so they just write a simple formula: amount * 2. Later they’ll make the scale factor adjustable.
Computed properties can reference other columns in the table
Our choice of JavaScript was motivated by convenience—it was easy to implement and easy to teach to people who already know JavaScript. However, we’ve applied some well-known design ideas from live programming and spreadsheets to try to make the environment friendly to program in. Each column computes a small pure expression that automatically re-evaluates reactively, and the current output is shown live in the table. We also provide built-in higher level functions for common high-level tasks that are cumbersome in JavaScript, like summing up a list of numbers. The result is that simple computations resemble small spreadsheet formulas, while the full power of JavaScript is still available to expert users.
Adding annotations
The user has computed a scaled value, but it’s not yet visible in the text document. They’d like to complete the scaler feature by covering up the original quantity with a scaled quantity. They can do this by setting up an annotation, which allows any column from a computation to show up in the text document.
Annotations don’t edit the original text content; they exist in a separate overlay layer. This preserves a clear separation between text and annotations, keeps the original text freely editable, and avoids circular feedback loops that could happen if annotations were themselves searchable. The visual design also differentiates between user input, displayed as normal text, and computational annotations, displayed with blue ink.
Annotations are placed in the document near the corresponding search result. The user can choose to place an annotation in one of several locations, each useful in different situations: Above Text, Next to Text, or Replace Text (shown below). When the “Replace Text” option is chosen, the annotation moves out of the way when the text editing cursor moves into the annotation, so that the underlying text can still be seen and edited.

Potluck offers several annotation locations: above the text, next to the text, or replacing the text.
In this case, the user tries out a few options for where to place the annotation, and decides to cover up the original text with the scaled value:
Interactive widgets
Now the scaled values are available in the text, but there’s not a nice interface for setting the scale factor within the text. Perhaps after making coffee a few times, our user gets tired of editing the formula each time and would like to add a slider interface to set how many cups they plan to make.
In Potluck, the user can use dynamic annotations to add interactive widgets which are built into the environment and exposed via special formulas. In the search panel, they can call a Slider() formula which returns a slider widget as a value, and then use the annotation mechanism to display it in the document.
Now there is a slider in the document, but its value does not affect the rest of the document in any way. The next step is to wire up the slider to the quantities. Previously the user hardcoded a scale factor of 2; they need to replace this with a computed expression that retrieves the value from the slider.
Potluck contains a number of helper functions that allow a computed expression to pull data from other searches. They can return to the quantities table where they previously hardcoded the scale factor, and instead retrieve the scaling factor from the other search that contains the slider. They get the slider value with the formula Find("scale").data.value, and put that in a column called scale. They can then replace the previously hardcoded amount * 2 with a new formula, amount * scale. Finally, they can add a unit label with JavaScript string interpolation: ${amount * scale} g.
This completes the working recipe scaler:
Using Find to reference a value from another search, so the slider will scale our quantities
In summary, we’ve seen how an interactive recipe scaler can be built in Potluck using a search for quantities, a computation that multiplies the quantities, and a slider widget annotation, all configured live within the tool.
Reusing searches
Next, our user wants to add another feature: a timer to help them track the coffee brew time.
They could build this up from scratch just as they did with the scaler, but because adding timers for durations in a document is a very general use case, they can instead reuse an existing search that someone else already made. The user opens the search panel to add a pre-existing search called duration, which recognizes duration strings like “2 minutes”. This search also comes with a predefined computed property that shows a countdown timer, which is another kind of built-in interactive widget.
Reusing searches is a key concept in Potluck, because many searches for things like numbers, durations, and even Markdown syntax are useful across domains. For these common use cases, people shouldn’t need to build everything from scratch. Reuse still allows for further remixing—the duration search’s pattern and computed property are defined in userspace, so the user can still edit searches and computations at any time.
Other features
Changing text styling
Sometimes, instead of using a computational result to add annotations to the text, it’s more helpful to change the styling used to display the text. Potluck supports this via dynamic formatting.
Consider the Potluck document below. It shows a watering schedule for house plants, including how often the plant needs to be watered, and when it was last watered.

It’s hard for a user to tell at a glance which plants should be watered today. One way they could solve this is by coloring dates in red if they’re too far in the past and it’s time to water that plant. The user can do this by adding a computed property which outputs “red” or “green”, and assigning that to control the color of the underlying search result. Any CSS property can be addressed by dynamic formatting, including color, font size, and font weight.
Dynamic formatting is reminiscent of syntax highlighting in code—in fact, the Markdown preview syntax in Potluck (e.g., bolding headings) is powered by this mechanism. The difference from syntax highlighting is that both the parser grammar and the formatting rules themselves are meant to be easily editable on the fly by end-users. For example, it’s straightforward to create a rule that a given word should always be highlighted when it appears in a document.
Editing the text programatically
Both annotations and dynamic formatting share an important characteristic: they are overlays applied to the text at view time, and they don’t durably edit the state of the underlying text in any way. We designed the system this way because it preserves a clear separation between the editable text content and downstream derived data, eliminating the potential for confusing feedback loops between the two layers.
However, we found that there were use cases where we wanted exceptions to this model. For example, in the plant tracker demo from above, every time we water a plant we have to remember today’s date in order to record it in the log. It’d be much easier to have a programmatic way of inserting today’s date into the text.
To support this, Potluck includes buttons that can insert or replace text in the document. Buttons are similar to other interactive widgets like sliders, but they have an additional capability for editing the surrounding text. The user specifies what should happen when the button is clicked: what text should be inserted, and where. Once the user has created a button, they can mark a plant as watered with a single tap.
💡 Try it: click the 🚿 button to mark a plant as watered
This button’s update behaves just like any other text edit—we get features like undo and redo for free. Furthermore, changing the text causes the parsers and formatting to rerun, updating the plant color indicators. Also, because the text edit only happens upon an explicit user interaction, it’s impossible to create runaway infinite loops where the computations and text update each other.
We’ve seen how users can extract data with searches, perform computation on the structured data, and inject annotations back in the text. Clicking a template button changes the text and starts the cycle again. Potluck’s interaction model turns static documents into an interactive and stateful computational medium.
Extracting spatial relationships
Now that we’ve seen a full loop of the interaction model, let’s briefly return to the first stage of data extraction. So far, we’ve seen the user extract relatively simple patterns, but in some cases, the document contains richer structure that requires the ability to establish looser spatial relationships between different parts of the text.
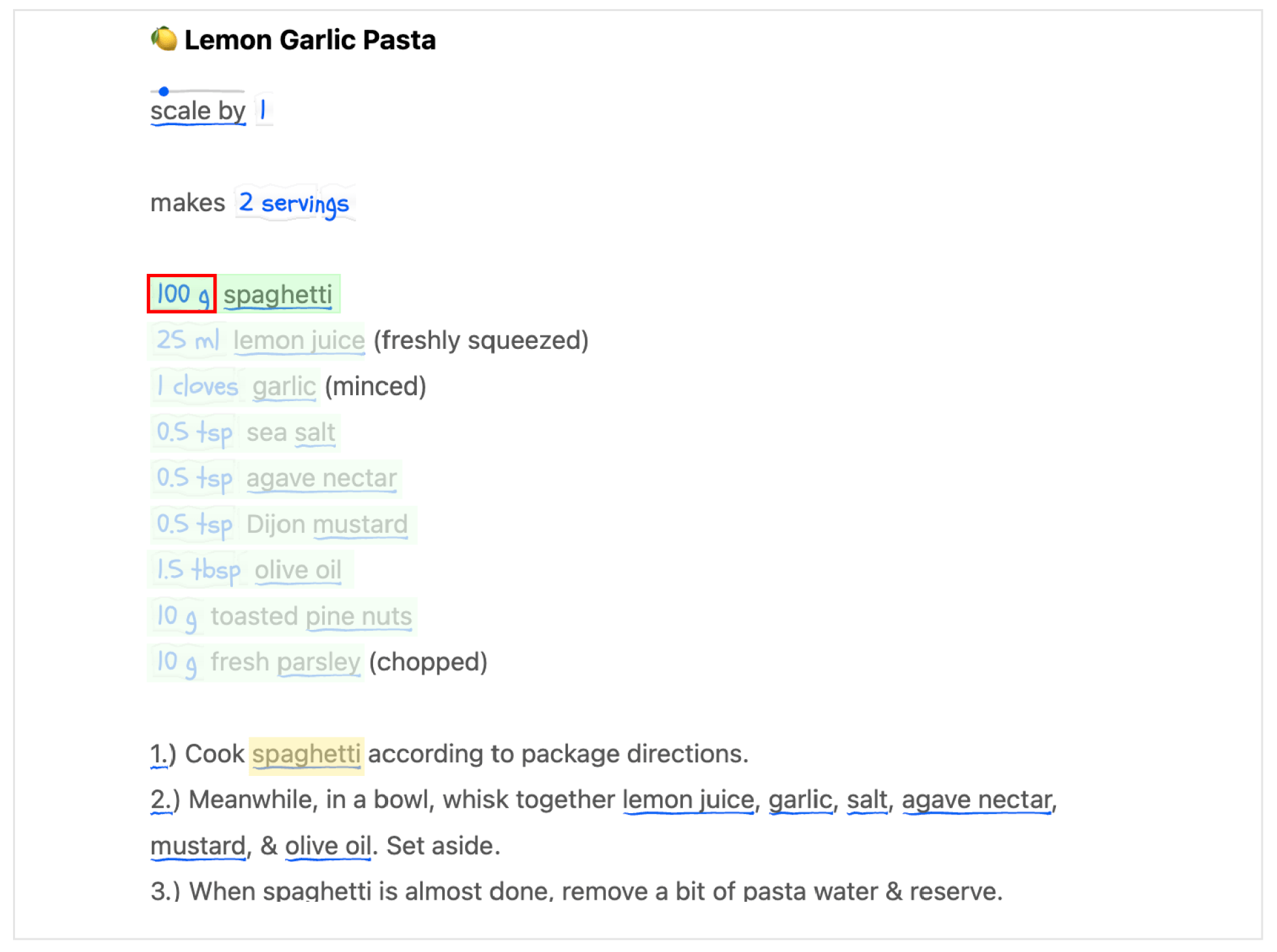
Consider the following example. A common problem with following recipes is looking up the quantity of a given ingredient while following the directions. It’s nice if we can see the quantities directly within the directions.

It’s more convenient to follow a recipe when the quantities are shown inline in the directions.
To support this use case, we need to start from an ingredient in the directions (e.g., “spaghetti”), and find the corresponding quantity in the ingredients section of the recipe. This relationship can’t be easily expressed in a pattern or a regular expression; we need a spatial query that can look across longer distances in the document. In this case, we can write a spatial query that runs the following logic: “Start from the ingredient name in the directions, get all previous ingredient names and take the quantity of the first ingredient with a matching name”:
Or, in code that we could enter into a Potluck formula:
AllPrevOfType(ingredient, "ingredient")
.find(other => (
other.data.quantity !== undefined &&
other.isEqualTo(ingredient)
))
We found spatial queries to be an essential tool for capturing relationships between parts of the text. For example, spatial queries can help associate a heading with the content underneath the heading, or help associate an ingredient with its nearby quantity.
Findings
We’ve used Potluck to build tools for ourselves, and have conducted informal testing sessions with about a dozen people, mostly programmers familiar with JavaScript. Here are some reflections from that process.
Versatility
A key question about this paradigm of gradual enrichment is how versatile it is. How far can you stretch these primitives, and when are they most useful? To explore this, we used Potluck to build documents for various use cases: tracking trip expenses, stock portfolios, planning trips, scheduling workshop agendas, managing a cash register, and more. (See the interactive demos in the introduction for some examples.)
In general, we found that the freeform nature of text made it possible to adapt Potluck to a wide range of use cases. Any text document, whether it contains prose or a structured personal micro-syntax, can serve as the starting point for an interactive tool. The medium is inherently permissive and flexible.
Meanwhile, some properties of Potluck—at least in its current form—limit the kinds of applications that can be built. Text must serve as both the input mechanism for the data and the substrate for designing the user interface, which obviously rules out applications with non-textual data or rich user interfaces and visualizations.
Working with fuzzy text data also increases the chances of errors—when reusing searches developed by someone else, it’s possible to write invalid data that isn’t recognized by the search. This is less of a problem in traditional software that performs stricter input validation.
Most of our example applications are also relatively small, with fewer than a dozen searches, each containing only a few computational columns. Even at this scale, we started to find it time-consuming to understand and modify tools built by others within our team. This is an unsurprising challenge that also emerges in traditional software and spreadsheets, but it suggests a need for better techniques to manage complexity.
Tool composition
We found that dynamic documents in Potluck naturally promote two kinds of composition.
The first kind of composition is reusing the same tool in different contexts. A timer can be used for remembering to take a pie out of the oven, or for holding a plank in a workout. A quantity scaler is useful in both recipes and event planning. Because all tools are made up of searches, tools, and annotations on a shared text substrate, it’s possible to reuse tools across documents.
Sometimes, simple tools like a timer can be trivially reused across documents; in other cases, we found it necessary to adapt or extend an existing tool. For example, often a search needs to be edited to support a different syntax. A quantity scaler might start out only looking for quantities in grams, and later need to be generalized to support more kinds of unit.
One unresolved design challenge is how to propagate changes across reused searches. In our prototype, changes to a search automatically affect all the documents where it’s used. This makes it convenient to improve searches globally, but also makes it very easy to break other documents when editing a search. We suspect a better approach would be to decouple the usage of a search in different documents.
A second kind of composition is combining multiple tools and domains in a single document. One document can contain information that might have been tracked in separate apps, like combining meal planning with an exercise log, or combining a trip agenda and group expense tracker in the same document. These kinds of combinations feel very natural in freeform documents, but are often difficult to achieve in traditional software.
In larger documents, especially those dealing with multiple domains, we found that it was sometimes useful to restrict a particular search to only certain regions of a document. For example, when a recipe document has notes at the bottom, it might be useful to have recipe-related searches apply to the recipe part of the document, but not the notes. To support this, we built a mechanism where searches can configured to only operate in part of a document.
Potluck vs. spreadsheets
We (and our test users) sometimes found ourselves preferring Potluck instead of a spreadsheet for performing simple computations.
One reason is that it’s common to start out writing information in a text document, and a text-based computational tool avoids the need to move the information to a spreadsheet. We also noticed that it often felt easier to edit data in text than in a spreadsheet. This might be because we’re more familiar with the affordances of text editors. Also, notes apps are more common than spreadsheets on mobile devices (and more ergonomic to use, since text wraps on narrow screens) which makes them convenient for editing on the go.
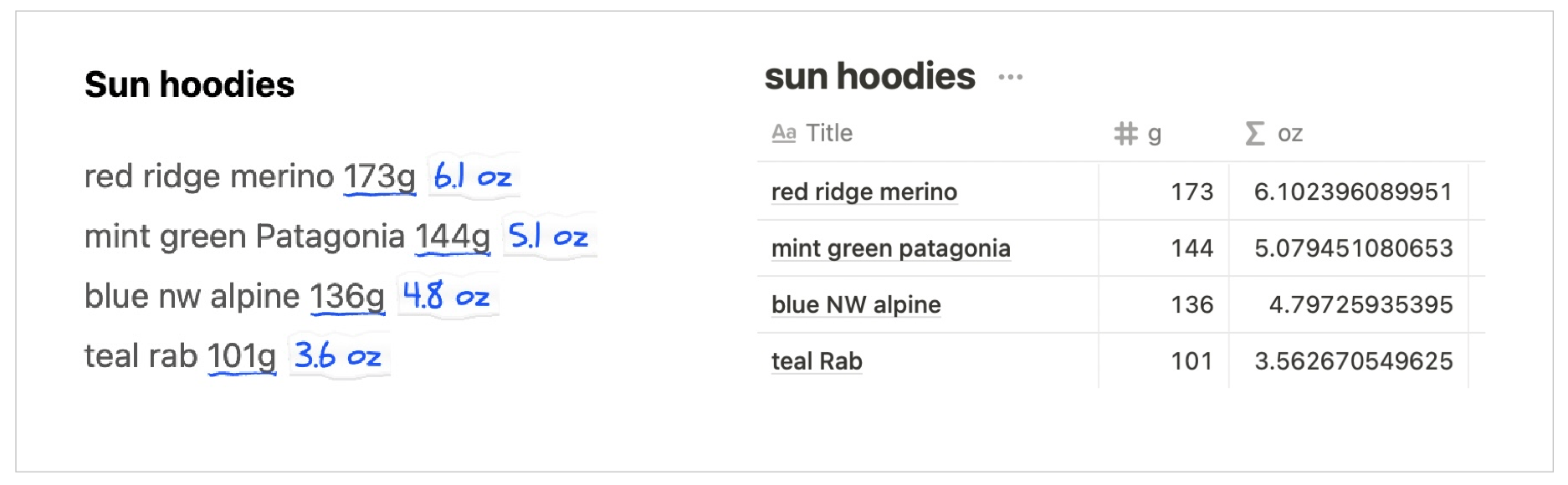
The same unit conversion computation, in Potluck on the left and a Notion Table on the right
However, in some cases Potluck felt more tedious than using a spreadsheet. Some documents contain many individual values which are hard to address using textual patterns; for example, the document below which lets the user enter 7 different variables as inputs to a calculator for a pizza dough:
💡 Try it: change some of the variables like dough balls, ball weight or water
In a spreadsheet it would be easy to just enter each of these values into a cell and reference the cell by name, but in Potluck, the user has to construct searches that can find these values in the text document based on some surrounding pattern. It’s possible we could improve upon this by extending Potluck with some mechanism for identifying named values within the text itself.
Challenges of parsing
A key challenge in Potluck is accurately parsing structured information from a text document. We noticed that the difficulty of parsing depends a lot on how the text content arrives in the document: it’s much easier to parse information from a personal micro-syntax being typed into Potluck than it is to parse preexisting content being pasted in.
Accurately parsing structured information from preexisting text data—like a recipe from the internet—is extremely challenging. For example, a recipe might call an ingredient “pork”, but later refer to it as “the meat”—how do you recognize that these are the same entity? These are difficult problems in the field of natural language processing.
The situation is quite different for personal notes typed into Potluck. When the user controls the shape of the text and is receiving feedback as they type, it’s much easier to create text that conforms to the parsers active in a given document. For example, if fractions aren’t recognized as numbers but decimals are, you can either edit the number recognizer to understand fractions, or just rewrite the text to decimals. Editing the search seems like the more principled choice, but in practice we often found ourselves editing the text because it was easier to do in the moment.
We also found it very natural to represent information using lightweight text syntaxes. In personal notes, people implicitly develop syntaxes to write down information like times, durations, or domain-specific information, and these conventions can be encoded in Potluck as patterns. For example, the plant watering document from the demo section above showed a simple syntax for recording watering dates. The figure below shows another example, where workout activities are grouped underneath dates. We found that Potluck’s combination of pattern searches and spatial queries was generally flexible enough to capture the underlying structure in many different kinds of informal syntax.

A personal micro-syntax for workouts: each workout belongs to the nearest date above.
State and UI in text
In Potluck, application state lives in the text. For example, you might note the last watered date for a plant using the text syntax 08/31/2022 , or use [x] to indicate a completed task. There is no hidden metadata; searches are just a function of the text.
Text editors are generic and refined tools that have many built-in features like copy/paste and undo/redo. Having state directly in the text gives us these features for free. For example, you can copy a document to a different text editor to edit and then paste it back into Potluck, and it retains all of its behavior. By using text as the source of truth, Potluck inherits the affordances and powers of text.
In some cases, our demos violate this general principle by storing ephemeral state which isn’t stored in the text. For example, our default timer widget doesn’t store the remaining time in the text, so a running timer won’t survive a copy-paste. This wasn’t a particularly principled decision though; in theory, any state that can be encoded as text can be stored in the document itself.
In Potluck, text also serves as the output medium for displaying computed data. We enjoyed designing tools in Potluck because the text medium forces a simple one-dimensional layout and avoids many of the choices found in conventional UI layout. Of course, there are limits to this approach—many kinds of apps and views don’t make sense to build using text as the substrate. But we didn’t notice these limits too acutely when building apps in Potluck, perhaps because we were already in the mindset of “writing a text document” and not “designing an interface”. Still, to extend the range of scenarios where Potluck is useful, one direction for future work could be to allow users to extend text documents with richer visual components.
Future Work
Structured data views
Annotations in the text can’t create more complex layouts or graphical visualizations. To address these shortcomings, we did some small experiments with structured views that are defined outside of the text. For example, here’s a text note recording recent workouts, with a calendar view that shows the dates of the workout in a more convenient format:

Showing a calendar view of a workout note in Potluck
One thing we found surprisingly useful in this experiment was to show context around each search result within the structured view. You can hover over any date and see the text from the original document surrounding that date, which makes the structured view a useful window into the original text.
We think it would be interesting to explore structured views in more detail. What is the relationship between text and structured data views? Do the views live inside of the document or are they separate from the text? As a starting point, people could connect their text notes to existing structured views, including generic views like calendars. As a step beyond that, we envision people creating their own views using some mechanism besides traditional programming.
Improving the formula language
Using JavaScript for our formula language was a scoping decision that allowed us to focus on Potluck’s core interactions rather than the details of expressing computations. Experienced JavaScript developers who tried the prototype were able to quickly pick up Potluck, and multiple people said that they had fun using coding in the live programming environment.
However, using JavaScript also limited the tool’s accessibility to non-programmers. We haven’t tested Potluck with many non-programmers, but the few that did try it unsurprisingly found it difficult to express sophisticated computations. To make Potluck more universal, we think it’d help to make the formula system more approachable with an emphasis on discoverability and debuggability.
The editing affordances of spreadsheets could be one inspiration here. You don’t need to know the syntax for referencing a range of cells; you can just click and drag the cells you are targeting. We believe there are opportunities for incorporating direct manipulation in Potluck. There might even be a design that allows for creating searches, computations, and annotations from the document itself without a separate sidebar.
Integrating machine learning
There are limits to how well the deterministic pattern descriptions we used in Potluck can interpret structured data out of text. For example, consider the difficulty of finding all the ingredients in a typical recipe—how do you decide on the list of known foods? How do you match up mentions of the same ingredient that use different words?
We think AI and machine learning could help solve these kinds of problems and make Potluck both more approachable and powerful. Recent advances in large language models like GPT-3 have shown the power of ML for interpreting structured information out of text. Some Potluck searches might be made both more accurate and more easily specified by writing them in natural language on top of a language model.

Extracting the ingredients from a recipe using GPT-3
Another role for ML could be in helping end-users write code for search queries and computations, using an approach like GitHub Copilot. This would still result in fast, predictable searches, but could make it easier to author them.
There’s a delicate tension between ML-based automation and maintaining user control. We’d want to avoid an approach that delegates too much work to an AI model; every step of the process should be repeatable, inspectable, and understandable.
Machine learning could also help extend the ideas of Potluck to other types of source material, like handwritten ink, photos, or video. Many of the same core ideas would apply: extracting meaningful symbols from freeform data.
Conclusion
In this essay, we’ve shown how searches, computations, and annotations can come together to enable users to gradually enrich text documents with structure and meaning.
While we’ve shown these ideas in the context of a specific research prototype, we don’t necessarily think that a new “notes app” is the right way to implement them. Perhaps these concepts could be more powerfully applied at deeper levels of the stack.
Imagine an operating system with the principles of Potluck deeply woven in. People could start by just organically recording information however they want. As they come across places where the computer could help them, they would gradually add structure to their data, but only as much structure as is needed for the task at hand. They would then add bits of computational behavior, borrowed from others or created from scratch, to complete the task.
The resulting tools might resemble “apps”, but in fact would be precisely tailored to one’s own needs. The tool fits the workflow, rather than the workflow fitting the tool.
In Potluck we’ve focused on text as the general-purpose medium for data, but the broader ideas could extend to other media as well. A recipe could be represented as a photo of a scribbled index card, processed with a combination of OCR and customized data detectors, with the annotations printed back onto the photo.

Applying the principles from Potluck, but to a photo rather than a text document
Ultimately, we want a world where people are in control of their computing experiences. People should be able to teach their computers the meaning behind their data, and choose how that data gets transformed and displayed in helpful ways—in service of adorning our computer-embroidered reality with hundreds of individual personal expressions.
If you’d like, you can try a live demo of Potluck. If you try making something, we’d love to hear from you.
We welcome your feedback: @inkandswitch or hello@inkandswitch.com.
Thanks to Maggie Appleton, Max Bittker, Glen Chiacchieri, Jonathan Edwards, Mariano Guerra, Josh Horowitz, Daniel Jackson, Szymon Kaliski, Clemens Klokmose, Cole Lawrence, James Lindenbaum, Nathan Manousos, Rob Miller, Alexander Obenauer, Josh Pollock, Mary Rose Cook, Peter van Hardenberg, Amelia Wattenberger, Adam Wiggins, and Daniel Windham for helpful feedback on this work.