
In the first lab note in this series, I introduced the task framework and motivated it with a few examples. In this note, I’ll give you a more concrete picture of the framework — the set of concepts you need to understand in order to use it — and walk you through its implementation.
Cast of characters
Each user has a pool of task workers that can run tasks from a set of task queues that user contributes work to.
A task is a unit of work. It has some code to run, an optional input, and a history of runs (success/failure, logs, and timing information). All of this information is stored in an Automerge document, the URL of which serves as the task’s id. Some tasks may generate a result, while others run for their side effects, e.g., modifying a Patchwork document.
Task queues enable users to organize tasks that are related in some way. As an example, there may be a task queue just for tasks that index Patchwork documents — this is where the embedding generation tasks from my previous note would go, and every user in Patchwork would contribute compute to this task queue. Some task queues are long-lived while others may be created for a specific purpose that is only temporary, e.g., the scenario-generation tasks for a particular Ambsheet.
The final piece of the framework is the task router, whose job is to assign tasks that belong to a specific task queue to users’ task workers. Each user runs a single router, but it can serve as the active router for one or more task queues simultaneously. Routers help the framework avoid running a specific task more than once, though this is not guaranteed — more on this later.
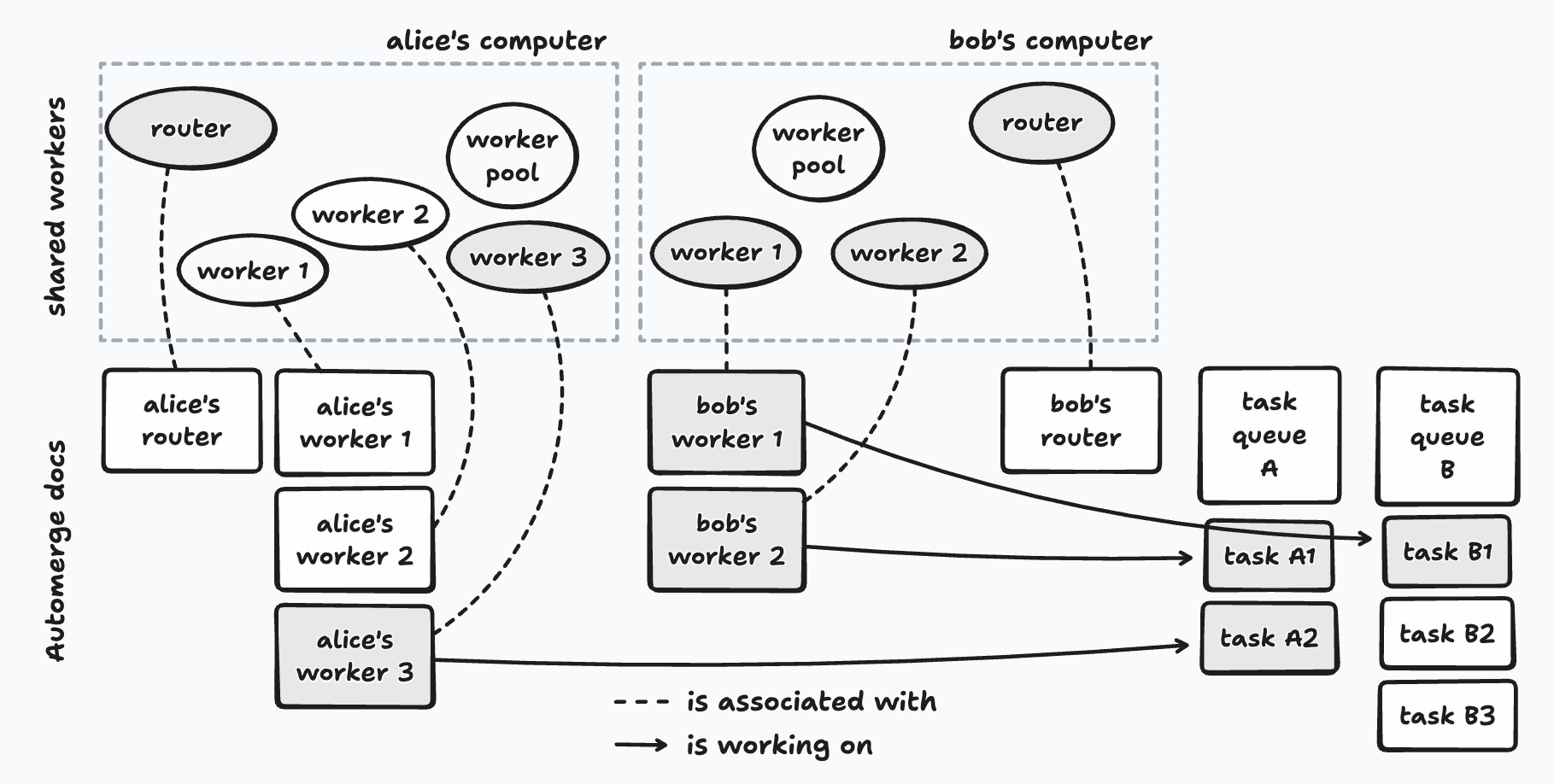
Alice contributes to task queue A; Bob contributes to both task queues A and B. Shaded workers are currently executing a task; arrows show which task they’re working on.
Note that the shared workers for the task workers and routers each have a corresponding Automerge document. These documents serve two purposes: (i) they give each shared worker a globally unique id that the rest of the system can refer to, and (ii) they provide a communication channel between shared workers via Automerge SharedWorkers can’t communicate with each other directly — messages between them would have to be brokered by the worker pool proxy. Ephemeral messages enable communication between the shared workers regardless of whether they are running on the same computer or on different ones, without any additional messaging infrastructure.
Coordination
These pieces don’t coordinate themselves — and doing it correctly, especially in the face of users going offline and coming back, is the central design challenge of the framework. Here’s how it works.
A user’s worker pool, task workers, and routers all run as SharedWorkers to ensure that each of them has its own thread of execution and separate memory space. These are all created by an object known as the worker pool proxy that is instantiated by a tool in Patchwork.
Note that each tab in the user’s web browser that is running Patchwork will have its own worker pool proxy, but opening a new tab won’t multiply the number of task workers or routers. This is because the names of these SharedWorkers are deterministic — e.g., task-worker-1 and task-worker-2 — and so the browser will reuse existing workers rather than create new ones with the same name.
The Worker Pool and its Workers
The SharedWorkers for the worker pool and its workers are created by the worker pool proxy. The following are the responsibilities of the worker pool:
-
Joining task queues. If the user wants to contribute to another task queue, the worker pool must join it. This involves opening a handle on the task queue’s Automerge document, which contains the list of pending tasks as well as the id of the task queue’s active router.
-
Registering task workers. When a task worker starts running, it creates an Automerge document for itself, which will contain information such as which task it is currently working on. It sends the URL of this document to the worker pool with an
add workermessage. (SharedWorkers can’t communicate with each other directly, so this message is actually sent to the worker pool proxy, which then forwards it to the worker pool’sSharedWorker.) When it receives this message, the worker pool opens a handle on the worker’s document. Now it can keep track of what the worker is up to, tell if it’s idle, etc. -
Keeping the active router of each task queue informed. The worker pool periodically sends heartbeat messages to each task queue’s active router to let it know what its own task workers are up to. The active router uses these messages to piece together a global picture of the state of the task workers so that it can assign pending tasks to the ones that are idle.
Routers and the “Takeover Protocol”
We’ve already seen how a task queue’s active router finds out which workers are available to take on tasks. But what happens when the active router goes offline? How does an inactive router become the next active router?
Recall that each user runs a single router, which subscribes to ephemeral messages from the Automerge docs of every task queue the user contributes to. The active router for each task queue will periodically send heartbeat messages through that queue’s channel. Other routers subscribed to the same queue will receive these messages and record the timestamp of the last heartbeat they received.
A router periodically checks the last timestamp it has received from each task queue’s active router. If it’s been a while (on the order of a few seconds in the current implementation), that router will assume that the active router has gone offline and attempt to take over as the new active router for that task queue.
This involves:
- Updating the task queue’s Automerge document to record itself as the active router.
- Waiting briefly so that the write can propagate to other peers.
- Checking if it’s still the active router, according to the task queue’s Automerge document. If so, it will start to (i) broadcast heartbeat messages to the routers belonging to other users that contribute to this task queue, and (ii) route pending tasks to idle workers.
All of the remaining routers will race to take over as the new active router. The information recorded in the task queue’s Automerge document is authoritative; any router that believes itself to be active re-checks that document frequently, and will stop routing tasks immediately if it sees that the document says otherwise.
It’s worth pausing on one consequence of this design: the framework guarantees that each task will eventually run, but does not guarantee that it will run only once. This is a deliberate tradeoff. When a takeover happens, it’s possible for more than one router to briefly think that it’s active, which can lead to the same task being assigned to different workers. So long as tasks are idempotent, redundant executions are not a problem.
The same dynamic plays out when a user goes offline. Routers belonging to users who are still online will notice that the offline user’s router has gone quiet and, if it was the active one, another will take over. But from the offline user’s router’s point of view, it’s the other routers that disappeared — so it will take over as active for its task queues too. This is essential: without it, any tasks added by that user while offline would never be serviced.
Up Next
In the next lab note in this series, I’ll introduce tasklib, the TypeScript library through which we interact with the task framework — creating and joining task queues, submitting tasks, and checking on their status.