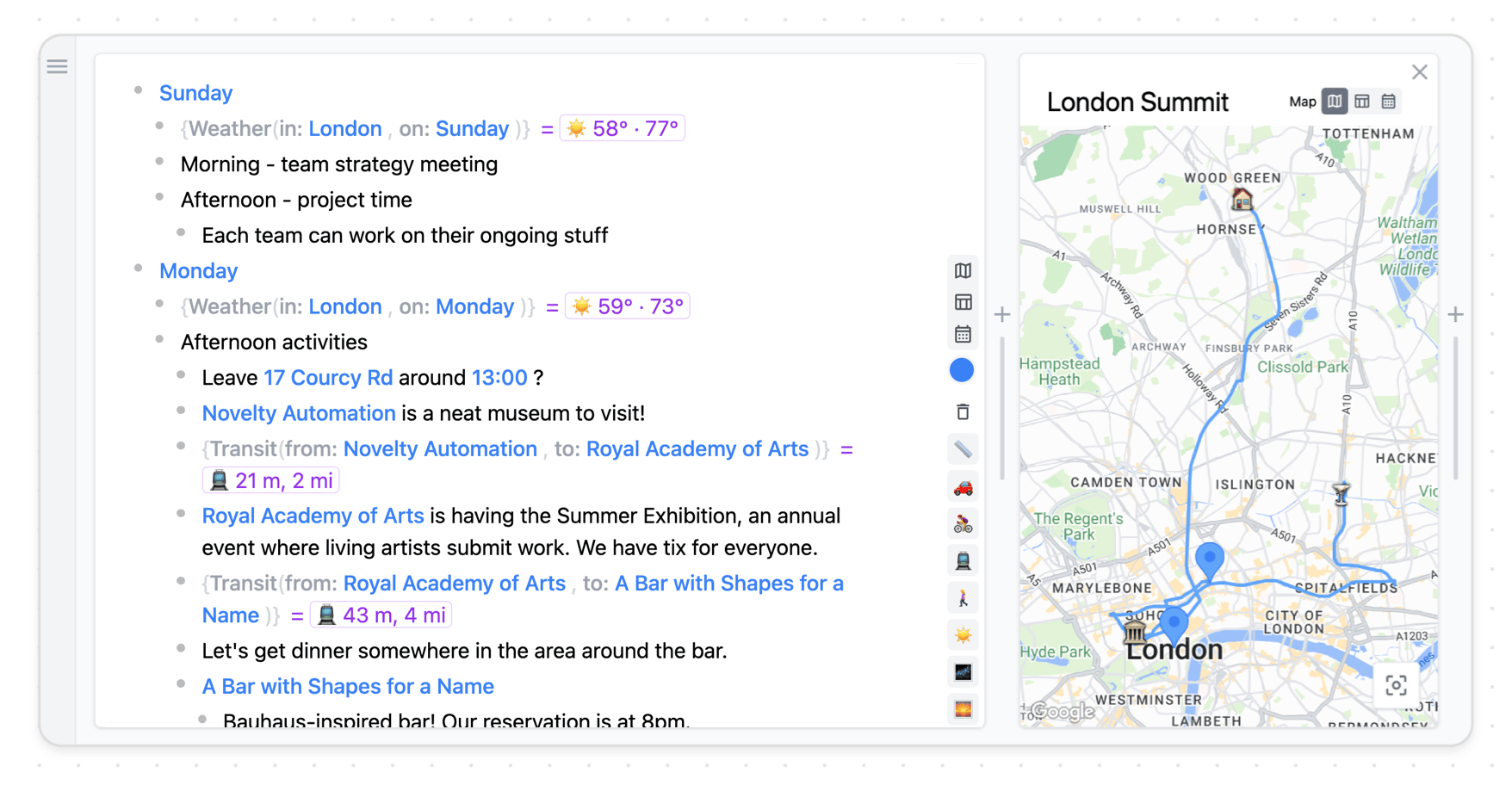

Planning a trip involves synthesizing information from many sources.
Motivation: the limits of siloed apps
Why is it so difficult to plan a trip using our digital devices? When making a plan of any kind, we need to pull together information from different sources, and then synthesize the information to make decisions. Although apps give us access to all kinds of information, they provide only limited mechanisms for bringing it together in useful ways. Whenever a complex task requires multiple apps, we are forced to juggle information across apps, resulting in tedious and error-prone coordination work.
For example, imagine Paul is planning a weekend with his friends, and they want to go canoeing. To plan a time and place for their activity, he needs to consider several related questions: What are some highly rated places to go canoeing? Which ones are most convenient to drive to? When will the weather be good? Can they make it home in time for dinner with his family?
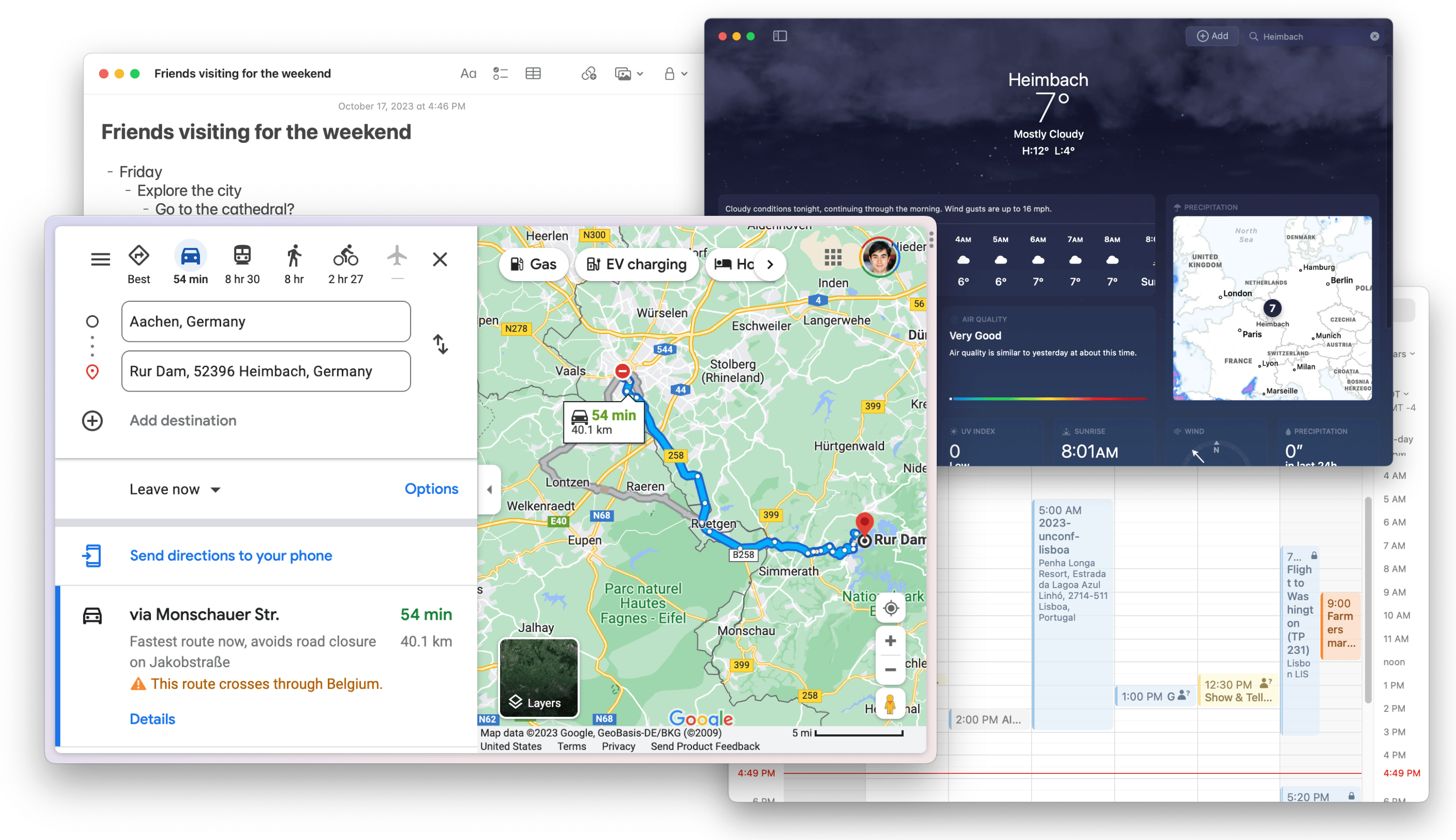
Planning a canoeing trip requires coordinating across many apps that don’t coordinate well together.
He can use individual apps to answer parts of these questions: an outdoor activity reviews app, a maps/routing app, a weather app, and a calendar app. But to put together the final plan, he needs to do a lot of coordination work between these apps, and encounters some frustrations.
Context is not shared across apps: Paul finds a list of candidate destinations in the reviews app, and wants to see the weather forecast for each one. But the weather app isn’t aware of the locations in the reviews app, so he needs to manually copy-paste the location of each destination into the weather app. To make matters worse, some of the locations are rural trailheads, but the weather app can only show forecasts for cities, so he needs to find the closest town to each destination. The problem is that the various apps don’t share the broader context of the task.
Views are siloed: The reviews app has a map of possible destinations, the weather app has a map of projected storm clouds, and the routing app has a map of driving routes to each place. Paul wishes he could see all this information combined on a single map to compare his options, but there’s no easy way to do this. Each app defines its own views that can’t be easily combined. Also, the map views in each app are mediocre because each individual application developer doesn’t have the resources to invest in making a great one.
Apps produce ephemeral output: Once Paul has decided on a best option for where to go, he wants to save his plan so he can remember the reasoning behind his decisions and update the plan in the future if needed (e.g. if the weather changes). However, it’s difficult to snapshot the information from all the apps and store it together—the best he can do is save some screenshots and URLs in a notes app. By default, applications produce one-time output and don’t make it easy to remember the process used to reach a decision.
Even in this small example, the limits of apps have become apparent. Each app works well in its domain, but is unaware of the broader context. And these problems will only get worse as Paul extends beyond the canoeing trip to consider the broader scope of his entire weekend plan.
Unbundling the app
A root cause of these problems is that applications tightly bundle together three things: data, computations, and views. For example, consider a mapping and routing application like Google Maps. It defines data types such as Location and Route, computations like Find Route, and rich views like Map. All of these parts are welded inside a closed world where parts can’t be swapped or remixed when they don’t meet the user’s needs.
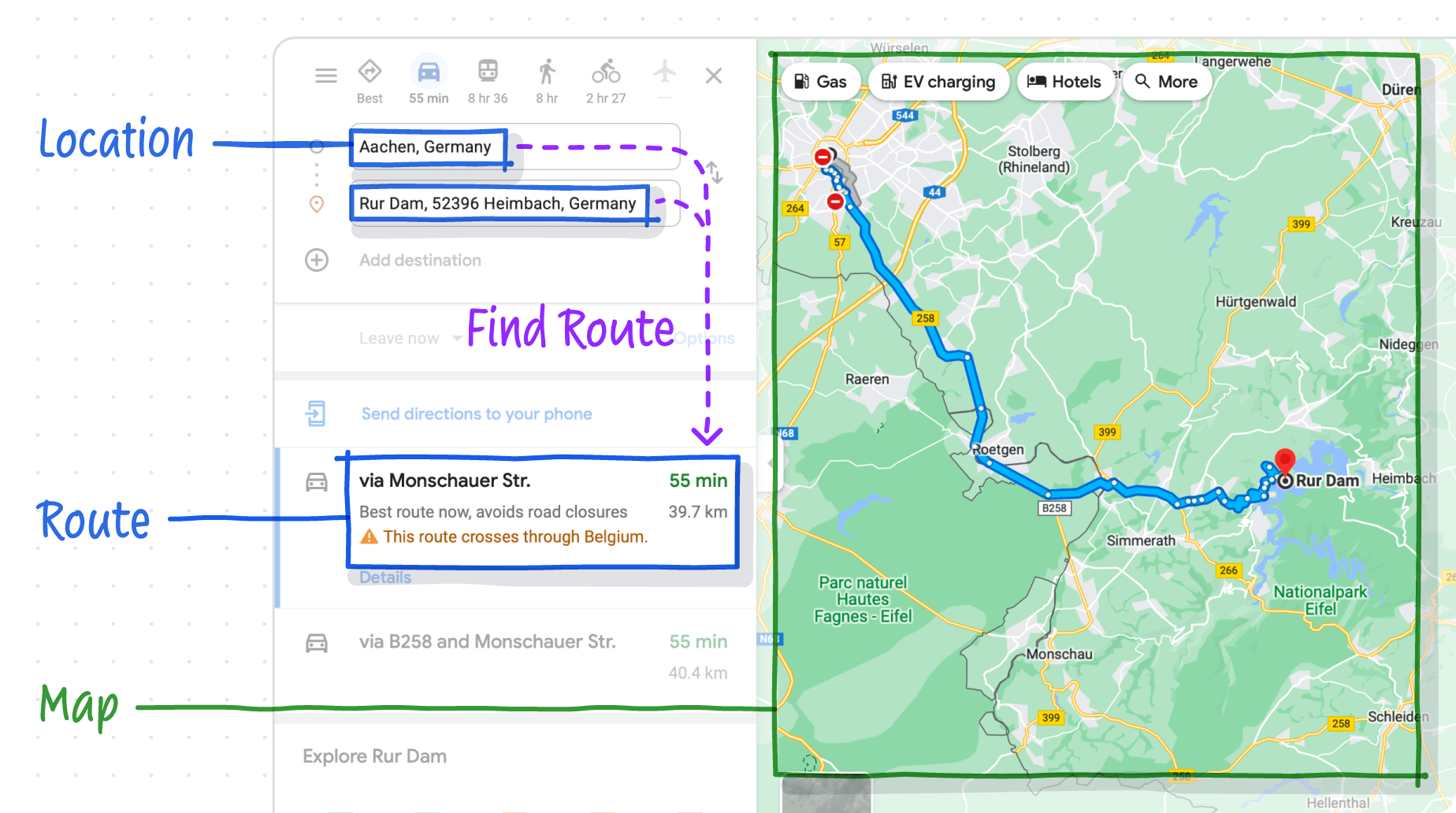
A mapping app consists of: structured data types (Location and Route), computations (Find Route) and views (Map).
One workaround for these kinds of problems is to find an app with a broader scope, like a travel planning app that combines wishlists, maps, routing, and more. These kinds of apps are convenient, but they still suffer from the challenges of the app model. It is impossible for companies to create apps for the infinite variety of combinations that emerge in real-world trips—a canoeing trip has different needs from an international business trip or a 3-month RV trek.
We think that fully solving these problems requires replacing the app model with a flexible environment where we unbundle the app into these component parts and allow users to recombine them on the fly. Each user would be able to assemble custom tools that exactly match their needs. This raises the question: where should data, views, and computations live? What might replace the app as a way of combining these parts?
Dynamic documents: enriching notes with behavior
One digital tool frequently used for planning is the text note. To plan his trip, Paul could open an app like Apple Notes to jot down information, think through pros/cons, and share his thoughts with his friends. Text notes have a few advantages compared to typical applications.
First, they are informal. Text notes support lightweight data entry. There is no rigid schema, so people can jot down any kind of information, in any shape they’d like: places, times, todos, foods to eat, people to meet, and more. A tentative itinerary can contain loosely specified times without the precision required by a calendar app. This is a stark contrast to the rigidity of apps, where the user must learn an entire taxonomy of concepts—itineraries, lists, dates, places—and operate within a highly structured environment.
Second, text notes are general—we can use them for all kinds of tasks. With a sufficiently general medium, people don’t need to learn an entirely new app from scratch for each task; we can simply use a text note to plan a trip because we already understand how the material behaves.
Finally, text notes create a persistent trace of a thought process. When we plan in a note, we naturally tend to expand downwards in the document. At the end, we end up with a trace of the process that was used to arrive at a given plan, instead of throwing away ephemeral output from apps.
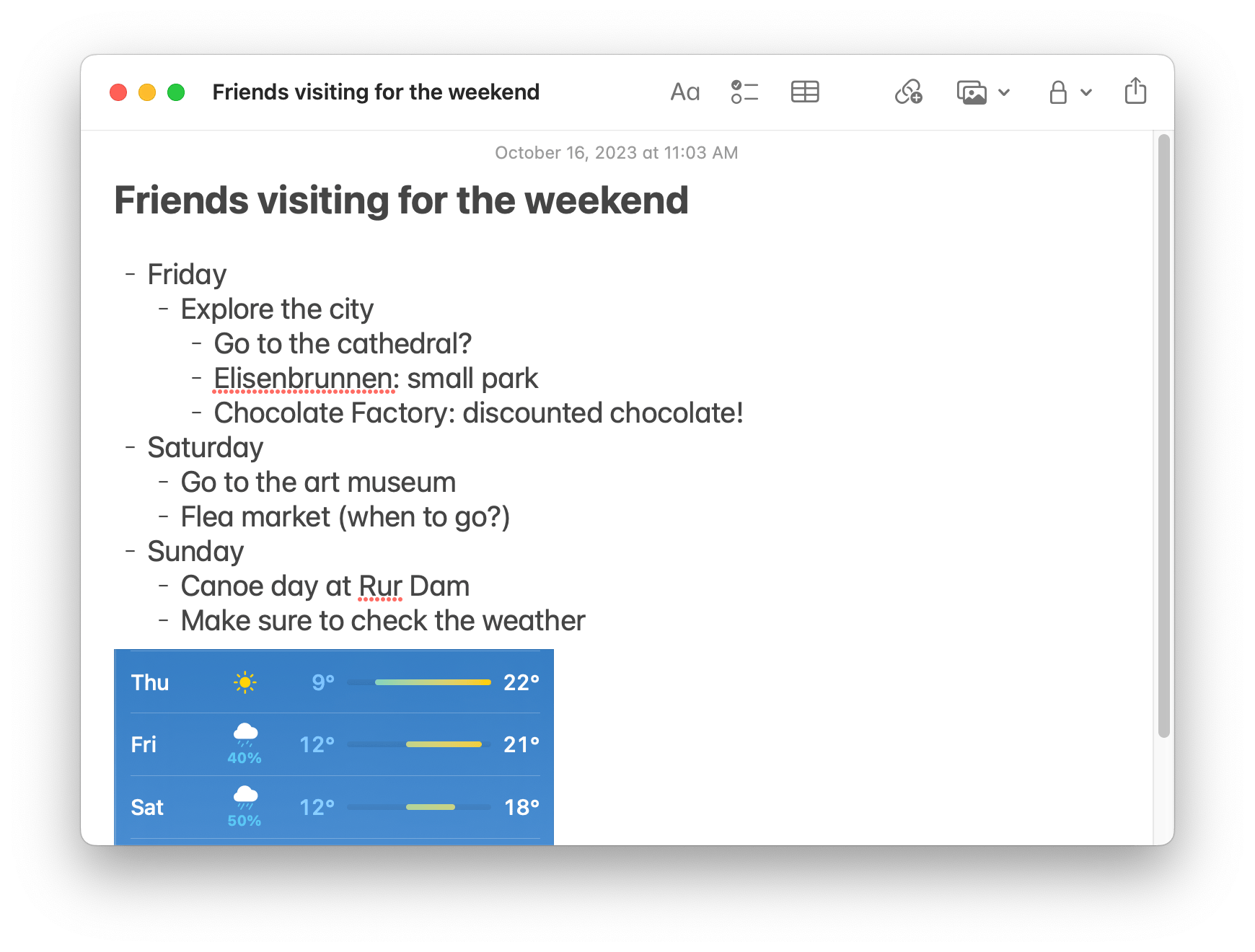
A text note is a lightweight way to plan a trip.
However, typical text notes have a major limitation: they lack dynamic behavior. When Paul writes down a travel plan in his note, he still ends up needing to switch to many other apps to look up places, book travel, explore routes, find weather forecasts, and more. Because the apps aren’t aware of his planning note as context, he still faces the same problems of manually copy-pasting contextual information between apps.
To archive the data from the apps, he can try to pull results into his note, but he only has limited options, such as copy-pasting text or screenshots. These are static artifacts—if the weather forecast updates, the screenshot doesn’t know. And if he wants to revisit the plan, he needs to figure out how to get the relevant application back into the appropriate state.
To overcome these limitations, we think a promising direction is to create a dynamic document medium which combines the best aspects of both documents and applications. This medium should allow users to jot down planning notes a lightweight, freeform way, and then gradually enrich these notes with data, computations, and views from other sources. Dynamic documents would make it possible to collect all the context for a planning process in a single artifact, easily pull in information from external sources, compute new information based on existing context, and visualize all of this in either textual or visual forms.
Ideally, all the tasks that people typically perform in apps could be done using tools embedded directly in the document. A user could start a document with a few sketchy notes about a trip, and end up with a fully fleshed out plan containing specific locations and times, maps and routes, weather forecasts, and more. The document would allow for exploring alternative options and changing the plan on the fly, leaving behind a durable trace of the whole planning process.
Prior art
In this section we review some techniques used in research prototypes and commercial products to support interactive dynamic documents.
Transclusion
Transclusion means embedding a view of a document within the flow of another document. This idea has a long history, from Ted Nelson’s Project
Transcluding a Google Map into a Notion document.
Many transclusion mechanisms have a key limitation: they only support shallow view embeds. For example, when transcluding several locations from Google Maps into a Notion document, it is possible to give each location its own map, but it’s not possible to combine these views into a single map. This is because the host is rendering a view without a deeper understanding of the data inside that view; transcluded components are mostly isolated from one another and from the host.
In contrast, some approaches to transclusion do support richer communication across embeds and hosts. In OpenDoc, tools installed in a host document could access data throughout various embedded parts: for example, a spellchecker tool could run across the text contents of all embedded parts of a document. Another example of deeper integration is in the outliner application Tana, which supports views like calendars and tables which pull information from an outliner document.
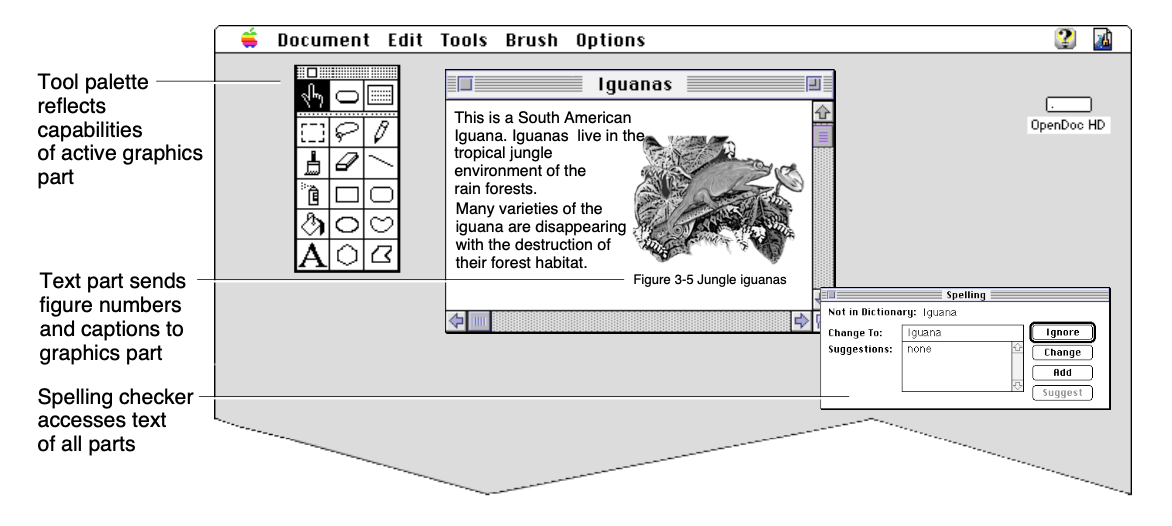
OpenDoc supported deep integrations between transcluded parts and host documents, such as a spellchecker acting across document parts.
Mentions
Mentions let users reference a structured object inline within some text. Products such as Notion, Coda, and Google Docs allow users to embed links within the flow of the text pointing to entities like people, dates, pages, or calendar events. Typically, users type “@” to trigger an autocomplete menu that lets them select an entity to mention; the mention then appears as a structured token within the flow of the text.
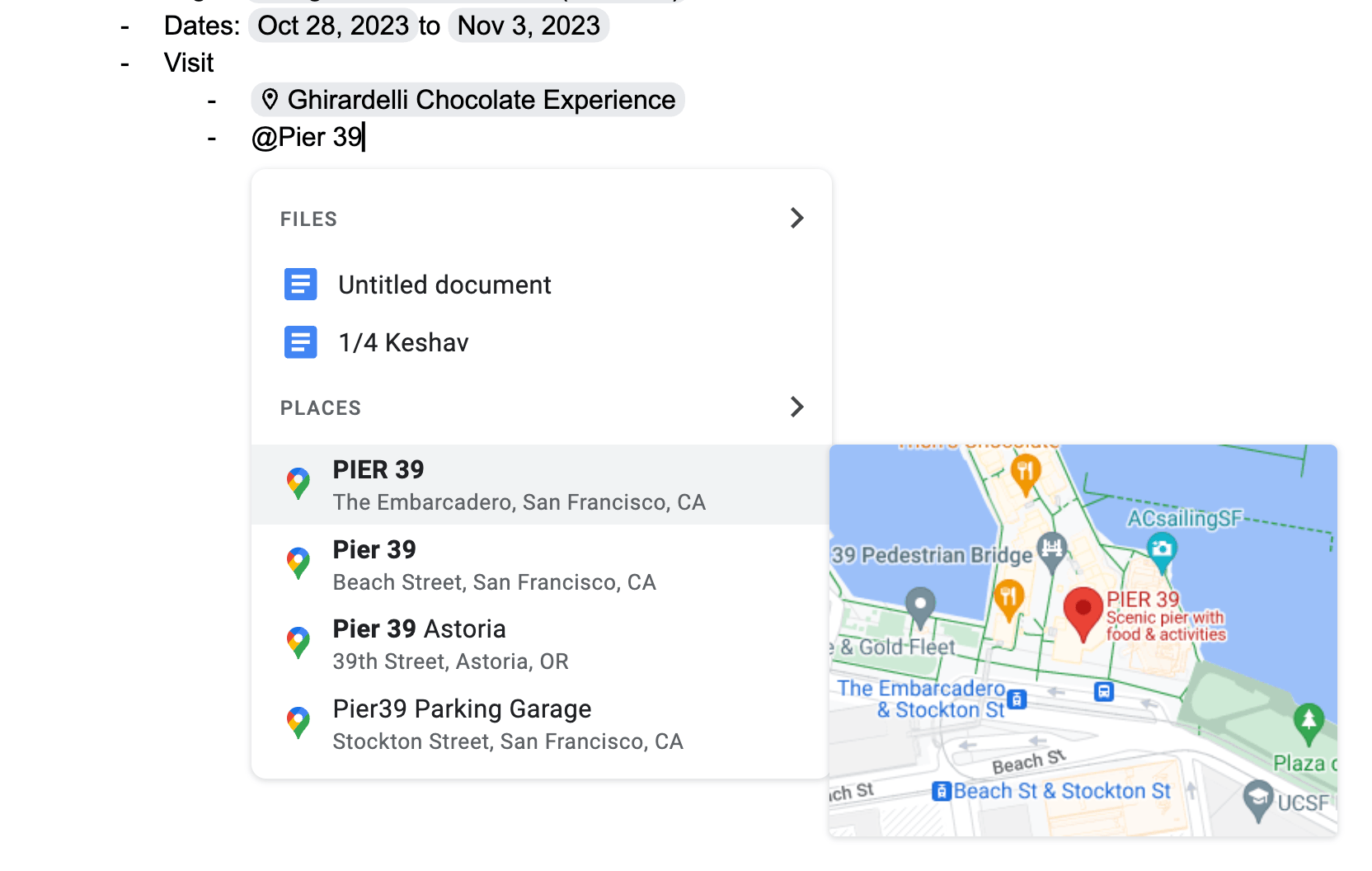
Adding a mention of a place to a Google Doc.
In most products, mentions can only be used in a small number of ways that the developers anticipated. For example, when a Google Doc contains mentions of two places on Google Maps, there is no way to compute a route between those two places, or show a single map containing both places. A more flexible system would allow using mentions in open-ended ways by passing them into arbitrary computations and views.
Structured properties
Another useful way to add structured information to a text document is to write properties representing attributes of an object. This feature is supported in various forms by modern outliner apps such as Logseq, Tana, Roam Research, and Obsidian. For example, in Logseq (shown below), named properties can be written down on nodes of the outline, and then users can query for nodes that match a specific property.
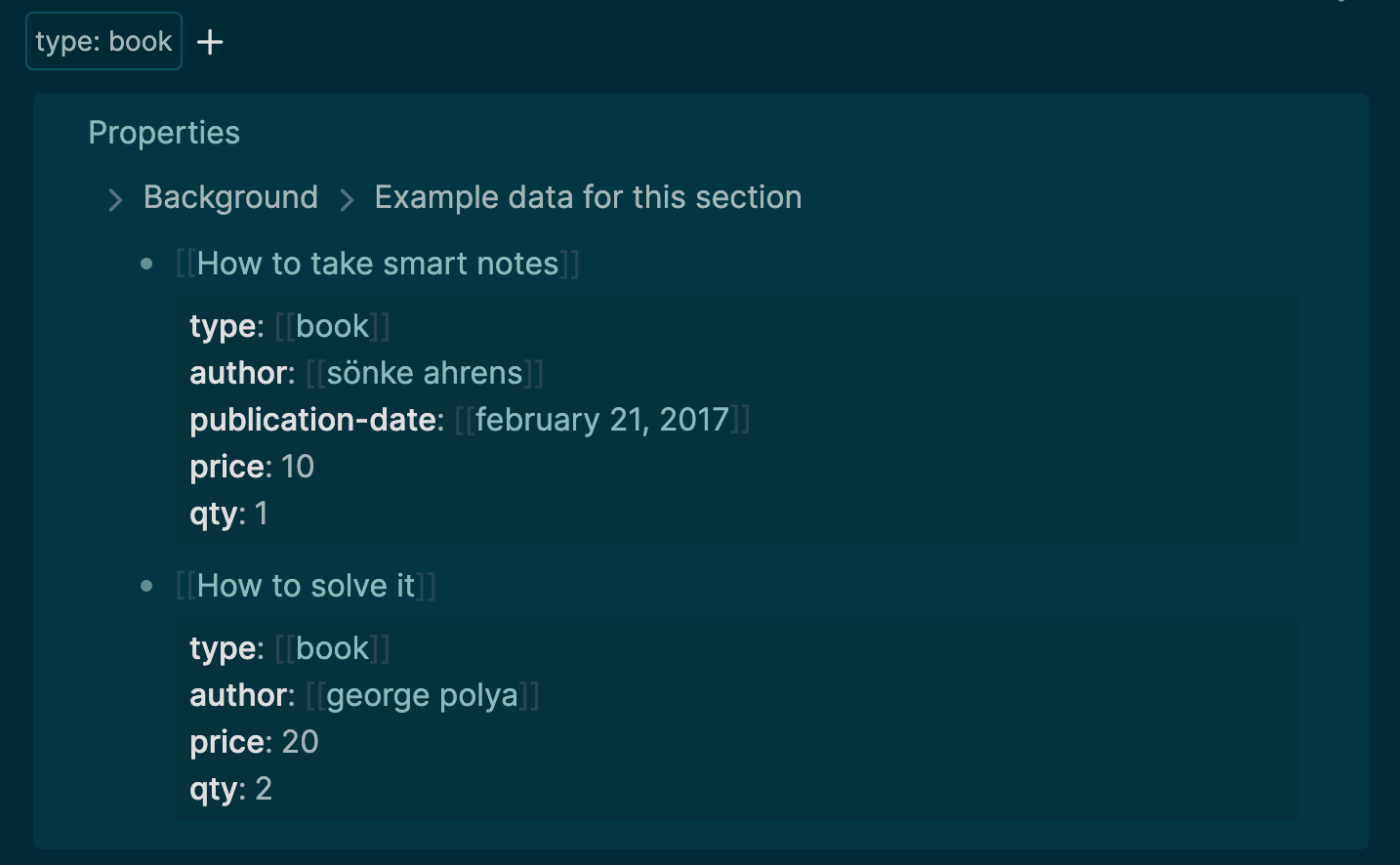
Querying for nodes that have the property ‘type: book’ in Logseq.
In Tana, users can define “Supertags” which define property schemas for entities like Person or Todo, which can then be assigned to nodes in their outline documents. This lets users reuse sets of fields and impose structure on entities they define throughout their documents.
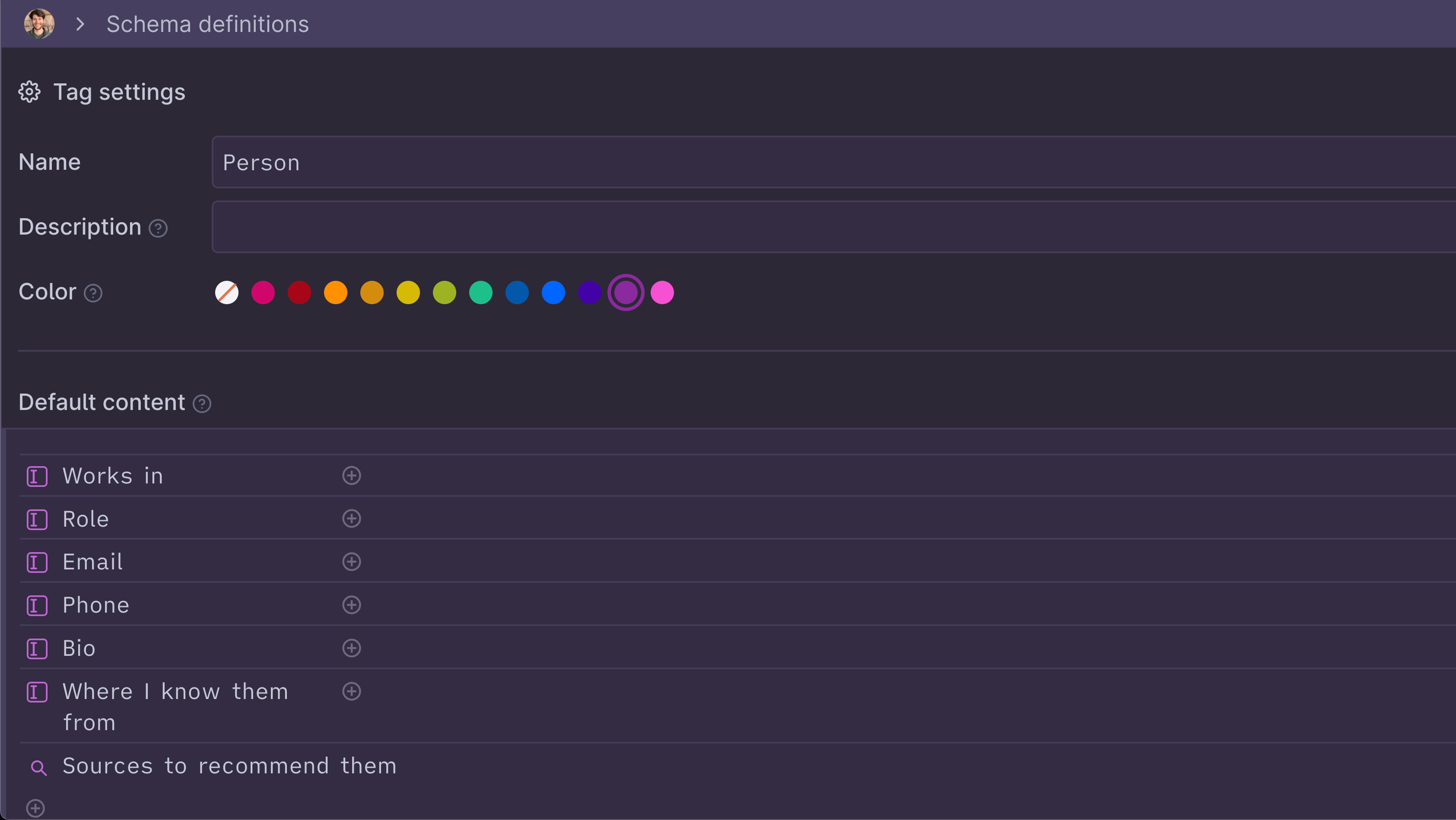
Defining a Person data schema in Tana.
Formulas in text
In spreadsheets, users can write formulas which take in data from surrounding cells and produce output values which react to changing inputs. This idea can be extended to writing formulas inline within a sentence of text.
Coda is one example of a product that supports inline formulas within a document. However, in Coda, while the output of a formula can appear within text, the inputs can only come from structured data tables.
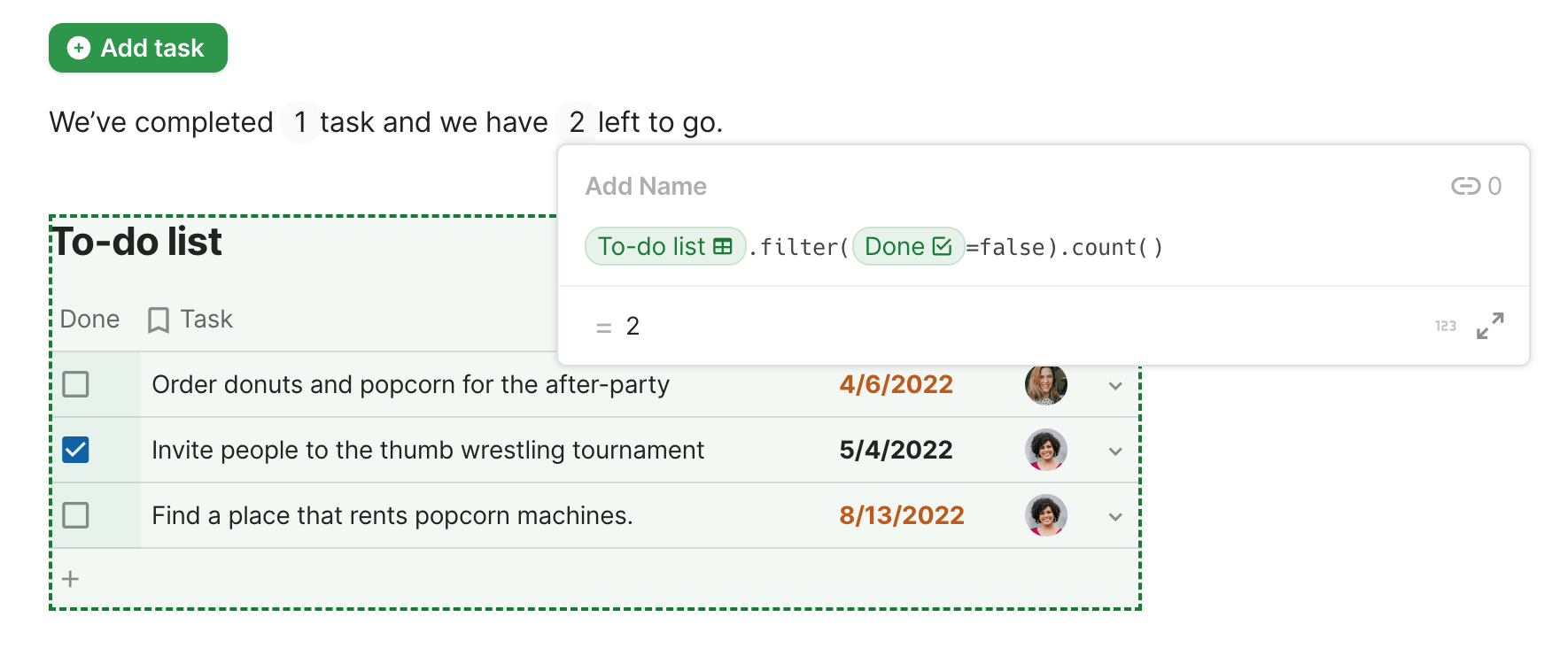
Writing a formula in Coda that operates on data from a table
In order to support informal thinking, we think it is important that formulas can pull in data inputs from the surrounding text document, not just fully formalized data tables.
Potluck
Previously at Ink & Switch we developed an environment called

A Potluck document configured to recognize quantities and durations within the user’s plaintext recipe
Potluck helped us validate the utility of dynamic documents as a category. We were able to build a variety of useful documents that helped with personal tasks like scaling recipe ingredients, tracking plant watering schedules, and setting timers for meeting agendas. However, we also encountered two key challenges.
First, we found that while the plaintext format worked well for very simple data, it made it difficult to represent structured data without resorting to cumbersome parsing logic. As a result, in this work we decided to use a more structured outline as the foundational data format.
Second, while we were able to make many demos in Potluck, we also found we did not authentically use it very much in serious contexts. For Embark, we made it a priority to use it heavily in real situations and learn from deep usage. One of the benefits of focusing on travel as a domain was that we had some trips planned during the design of the tool, so we could incorporate learnings from real use.

Embark: dynamic documents for making plans
To explore the utility of dynamic documents, we built a research prototype called Embark, focused on the domain of travel planning. We designed it to embody the following qualities:
- A record of your thought process: The document should help the user navigate the decision-making process, by serving as a central hub for gathering information and writing down thoughts. Instead of spreading relevant information across ephemeral sessions in disconnected apps, the entire process should be represented in a single saved workspace.
- Gradual enrichment: A document should always allow for freeform expression without needless structure or fuss, while also allowing the user to incrementally add structure and computations to enrich the document with dynamic behavior where useful.
- Separate data from interface: Structured information should be available to the system in a raw form so that it can be displayed in multiple views and made available to computations. This also allows data from multiple sources to be combined in the same view; e.g., combining multiple routes onto the same map.
- Shared context across tools: Tools shouldn’t operate in a vacuum; they should be aware of the broader context of the task at hand. Background information like the dates being considered for a trip should be accessible by tools like a weather forecast lookup.
- User agency > automation: The goal of the document is not to automatically make decisions on behalf of the user. Rather, we seek to make it easy for the user to gather the necessary information and make their own decisions while recording their thoughts in a document.
To focus our research on designing useful interactions and mental models for dynamic documents, we ignored several important issues in this work: we assumed that all tools share common data schemas (which is not true of the real world) and we did not prioritize principled integrations with the existing world of real apps and data. Instead, we allowed ourselves to imagine a world where all tools were built on top of a foundation of dynamic documents.
Conceptual model
The basic data model of Embark is an outline where text can be organized in nested bulleted lists. We then add three features which allow the outline to be gradually enriched with dynamic behavior:
- Mentions
Mentions let users link to entities like places or dates, inline within the text. A mention is just a link to another part of the outline. The system imports data from external services like Google Maps into the user's outlines so that mentions can link to external data. - Formulas
Formulas allow users to fetch live data like weather forecasts or perform simple calculations from within the outline view. Formulas can pull in data from the surrounding outline, and they return outline nodes which can be chained into further calculations Our formulas resemble spreadsheet formulas, but with rules for referencing values within an outline instead of a grid. - Views
Interactive views can render data from any subtree of the document. For example, a map view can show the locations and routes for a given day of a trip, or for the entire trip. Views can be opened inline within the document, or next to the document.
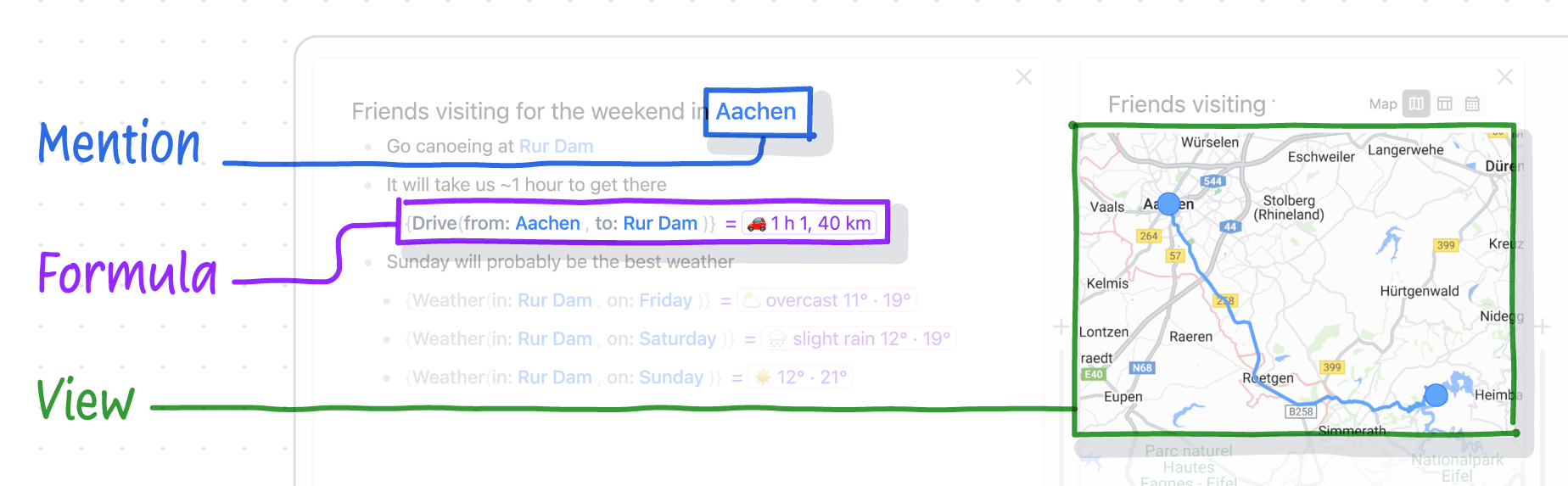
Finding a route within an outline using mentions, formulas, and views.
These three primitives roughly correspond to the parts of an app that we described earlier: data types, computations, and views. Together, they turn an outliner document into a computational tool that combines the best aspects of both freeform documents and traditional apps.
Mentions: linking between nodes
To see these primitives in action, let’s explore a real scenario that one of us, Paul, encountered: planning a weekend with some friends. His friends were visiting his hometown of Aachen for the first time so he wanted to plan some fun activities.
A few weeks before the visit, Paul wants to jot down a few notes about the trip, like when his friends will arrive, and some ideas for activities that they could do together. In this early stage, he is not thinking about specific days or times or making firm decisions. He can start writing his preliminary thoughts by simply typing text into the outline.
When he wants to reference certain kinds of structured objects like a place or a date, he can create a mention by typing “@” and picking a choice from an autocomplete menu. Mentions are simply links to other outline nodes containing structured data. For example, when Paul chooses “Chocolate Factory” from the autocomplete menu in the example below, the system automatically creates an outline node and populates it with information pulled from Google Maps.
Adding a mention that references a place imported from Google Maps.
Paul can click on the mention to view or edit the linked outline node. When he clicks on the linked node, we see that its children contain structured information stored in named properties, like rating: 4.7. Embark has a lightweight syntax for such properties: any outline node can have a name, using the syntax name: value. These names can be manually written by the user or filled in by automatic data importers.
A place is represented as an outline containing structured data, which is user-editable.
So far, mentioning places has offered some minor improvements over simply writing place names in plaintext. When Paul wants to remember the address or some other information for any of the places mentioned in his plan, he can click on the mention to quickly find this information. But we will see much more powerful uses of mentions later on, when they help the environment make sense of structured information to power views and computations.
Views: showing rich visualizations
Next, Paul wants to share the plan with his friends and include a map as a visual overview. He can do this by adding a map view, which reads in any nodes containing location information and displays them as markers on the map. The place mentions he created earlier appear on the map because they contain location coordinates imported from Google Maps. Looking at the map, Paul can see that most of the activities are within walking distance; only the chocolate factory and the art museum are further out.
Viewing locations from the outline on a map view. Embark syncs hover and focus state between the outline and the map to make them feel connected.
The map is just one instance of a view; Embark also includes a few other simple views including tables and calendars. Each view instance is associated with some node in the outline and can access any data in that node or the subtree underneath.
Views can also be displayed inline as part of their associated node. This makes it easy to create different views for different subtrees in the outline—for example, if Paul wants to split the activities across multiple days, he can create a separate map for each day so his friends can quickly see where they need to go.
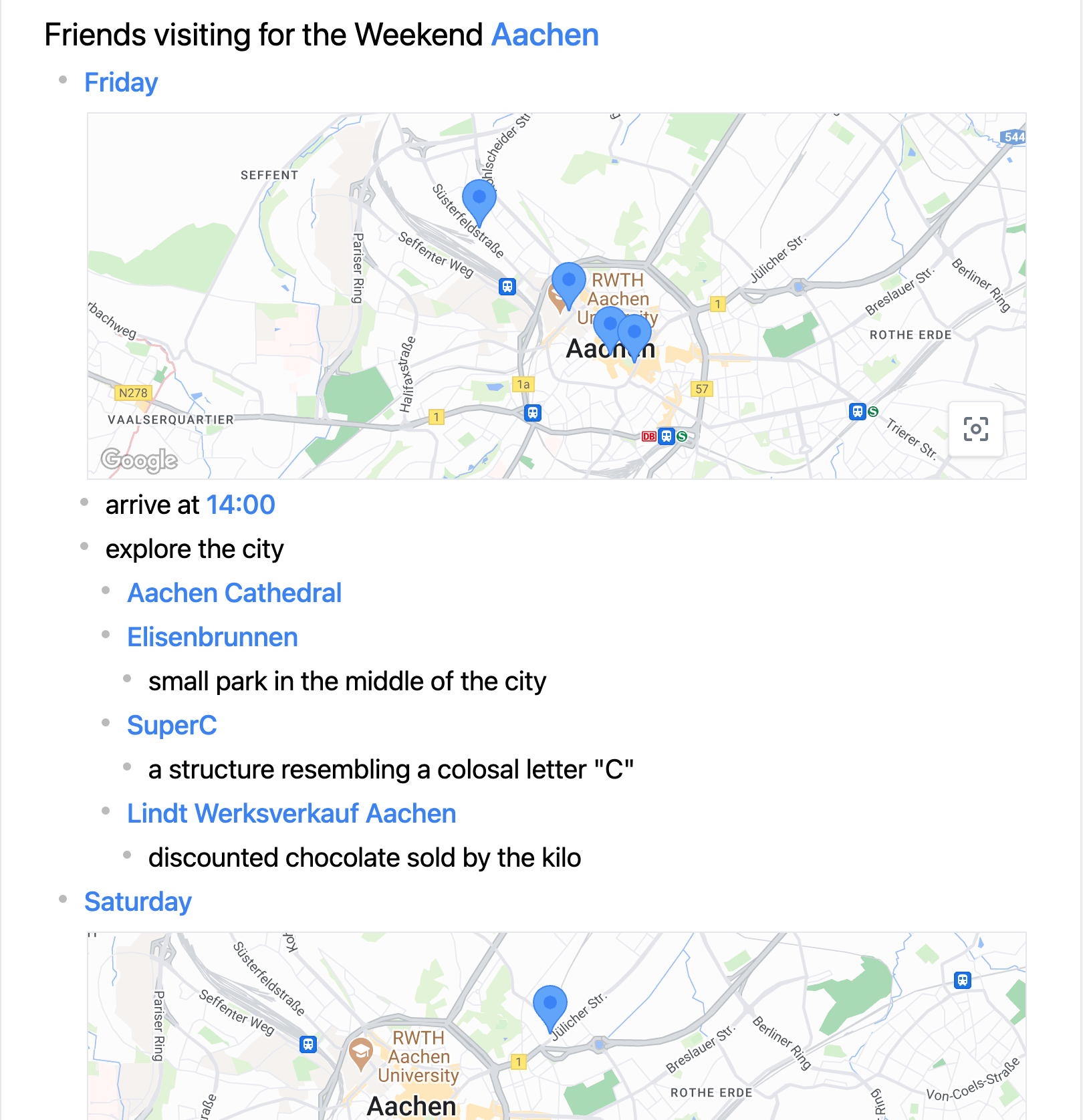
Viewing locations in separate map views for each day of the trip.
Views are not limited to accessing data created by automatic importers; they can also access data entered manually by the user. Paul can take advantage of this to customize his map further.
First, he wants to show some custom icons for various points they are visiting. He can do this by adding an “icon” property to some of the places they are visiting, such as adding an icon for the cathedral.
Editing the map icon for a cathedral by adding a property in the outline.
Another customization Paul wants to make is to color-code the points that his group will visit on different days of the trip. Because his outline is already organized hierarchically by day, he can set a color property for various sub-trees of the outline, and the map will color the points taken from that tree.
Changing the color of map points by setting a color property in the outline.
The colorpicker example illustrates two key features of Embark.
First, there is a direct manipulation interface for setting a color, but all it does is set a color property in the outline, which is then picked up by the map view. The outline data structure serves as the foundation for coordination between various controls and views.
Second, setting a color on a node conveniently sets that color for the entire subtree under the node. This works because property values are resolved using the outline hierarchy. When a location shown on the map doesn’t have a color property set, the system looks upwards in the outline tree until it finds a color in a parent node.
Formulas: performing computations
Next, Paul and his friends need to consider the weather for outdoor activities, plan modes of transportation between stops, and generally put together a sensible itinerary.
Answering a question like “what will the weather be for our canoeing trip” requires using information that is already present in the outline, like a place and a date, and deriving some further information from those inputs. To support these kinds of use cases, Embark offers formulas: dynamic computations that use data from the outline as inputs and produce further outline nodes as output. Users can always write formulas manually as in a spreadsheet, but Embark also offers affordances for automatically suggesting formulas.
First, Paul wants to get a weather forecast for Friday. When he clicks on the node for Friday in the outline, the UI suggests formulas that could apply to this node, including the one he wants: Weather(in: @Aachen, on: @Friday). To power this suggestion, the system uses a heuristic that examines the surrounding context in the outline to recommend useful formulas. In this case, Aachen was mentioned in the top node of the document, so the system used that as the location input.
Inserting a weather forecast for Friday into the outline.
The formula and its result now show up in the outline. The results will automatically update as the weather forecast updates. Paul can move or annotate the result just like any other outline node.
The result of the weather formula appears with a text preview: “⛅️ overcast 11° · 18°”. But underneath that display output, it is actually just a special kind of mention which links to a read-only outline node containing structured properties. Later on, we will see how the properties inside this result can be accessed in further computations.
Auto-repeating formulas
Next, Paul wants to get the weather for all the days of the trip. He could achieve this by redoing the same process manually, but Embark also offers a faster way: a repeat button that automatically copies the formula to various parts of the outline, while changing the inputs to match the surrounding context for each copy. For example, the weather formula keeps the same location, but gets a new date to match each date of the trip.
Repeating a formula throughout the document based on a structured pattern
Under the hood, the repeat button works by inferring an abstract pattern for the formula based on how its arguments relate to the outline. After inferring this pattern, Embark tries to find other places in the outline that match this shape and insert a formula using the matched nodes as arguments to the function.
An important design decision we made is that Embark’s heuristics for suggesting and repeating formulas are ephemeral—they run a single time when the suggestion or repeat is happening. Once the formula has been inserted into the document, its arguments are bound to mentions which reference specific outline nodes and do not depend on the shape of the document. We designed it this way so that future changes to the document wouldn’t cause unpredictable changes to formula behavior. Even when the suggestion or repeat heuristics are inevitably imperfect, the user can clean up the formulas manually and remain confident that they won’t be updated automatically.
Auto-suggesting formulas
On Sunday the plan is to go canoeing. This is a bit further away, so Paul must figure out how to get there. His first step is to choose whether to drive or take public transit. He can do this with a routing formula.
So far, he has been using the automatically suggested formula buttons, but he can also add formulas by typing “/”, which pops open an autocomplete dialog that can be filtered down quickly using a fuzzy text search. Paul uses the autocomplete menu to view different transit options for getting from Aachen to Rur Dam. The menu shows him previews of the time it will take to drive, take transit, or walk (computed by the Google Maps API).
He concludes the best option is to go there by car, and adds the Drive formula to his outline. The result of this formula displays the time and distance expected for the drive. Internally, it contains more structured data, including a geographic path which can be displayed by the map.
Comparing transit options for getting to Rur Dam.
Composing formulas
Now that he’s decided to drive, Paul wants to figure out how much it will cost to rent a car for the trip. He can do this by writing some formulas that perform math calculations based on the output of the route formula.
First, he assigns the name “route” to the outline node with the route computation, which lets him refer to it from other nodes. He can then write new formulas which use the distance of the route to compute the price based on the cost per kilometer (30 cents) and the fixed daily rate (25 Euros). The formula language has a syntax route.distance for accessing named children of the mention returned by the formula result.
Estimating the cost of renting a car using math in formulas.
This example has shown that chaining together formulas can enable useful kinds of composition. In most apps, computations like routes only show up in a specified view; in Embark, they return structured data into the outline, which can be displayed in standard ways or repurposed for more custom purposes.
Overlaying multiple data sources
Next, Paul needs to decide how to schedule the activities on Saturday: an indoor art exhibit and an outdoor flea market. He needs to take into account both the weather forecast and the hours the flea market is open.
Because the result of the weather forecast formula above is a mention containing structured data, it can be passed into a view and combined with other data. Paul can use a single calendar view to show the hourly precipitation probability from the weather formula alongside the opening hours of the flea market that he manually entered into the outline.
When Paul looks at the calendar, it becomes clear that he and his friends should go to the flea market first because it’s less likely to rain in the morning.
Showing scheduled events and weather forecast information on a single calendar view
Composing data from multiple sources in this way is harder to do in the conventional app model. For example, if you open Google Calendar and pull up the weather forecast in another tab, there is no way to combine these two data sources in a single view. This is possible in Embark because the weather forecast and the time information live in the same data substrate. A structured view like the calendar view can read both pieces of information as time ranges.
Liveness: updating the plan
Paul has now completed his plan for the weekend. All the results of his planning are accessible in a single document with an outliner itinerary as well as map and calendar views. He can continue to come back and reference the document as the weekend is underway.
Because this document contains live computations and not static screenshots, updates to external data will automatically propagate into his document over time. Each time he loads the document, it can show an up-to-date forecast and up-to-date routing estimates using the latest traffic conditions.
As his plans evolve he can edit the document and adapt it to the latest state of his trip. If his friends decide to change the plan during the trip, they can revisit the document and quickly update routes or times to fit their new schedule.
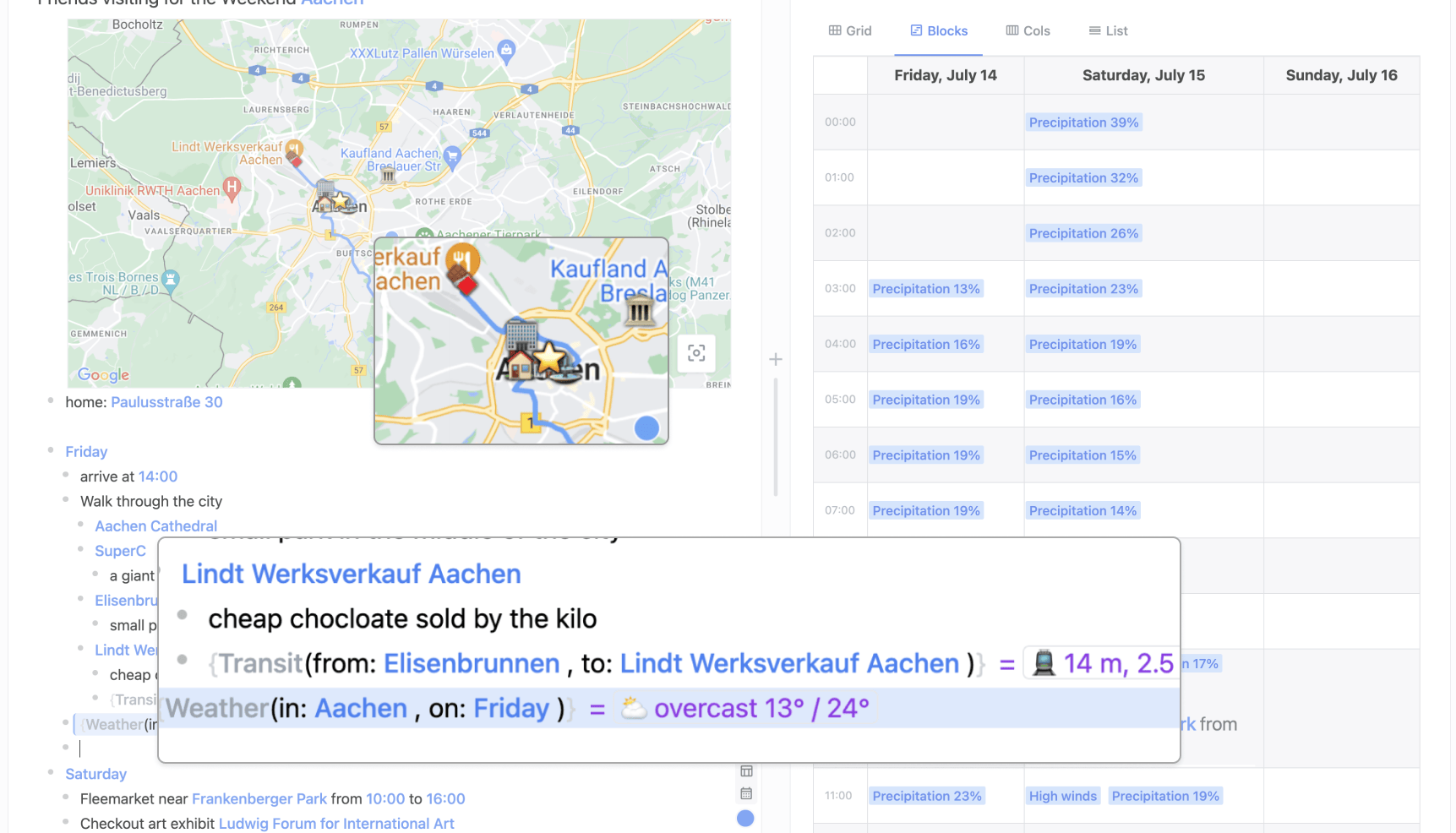
Paul’s final weekend plan includes an outline itinerary, a map, and a calendar view
Findings
A main goal of our project was to learn from actually using Embark. Throughout the course of the work, we used the tool in a variety of authentic travel planning scenarios. Here we briefly describe some of these trips, and what we learned from them.
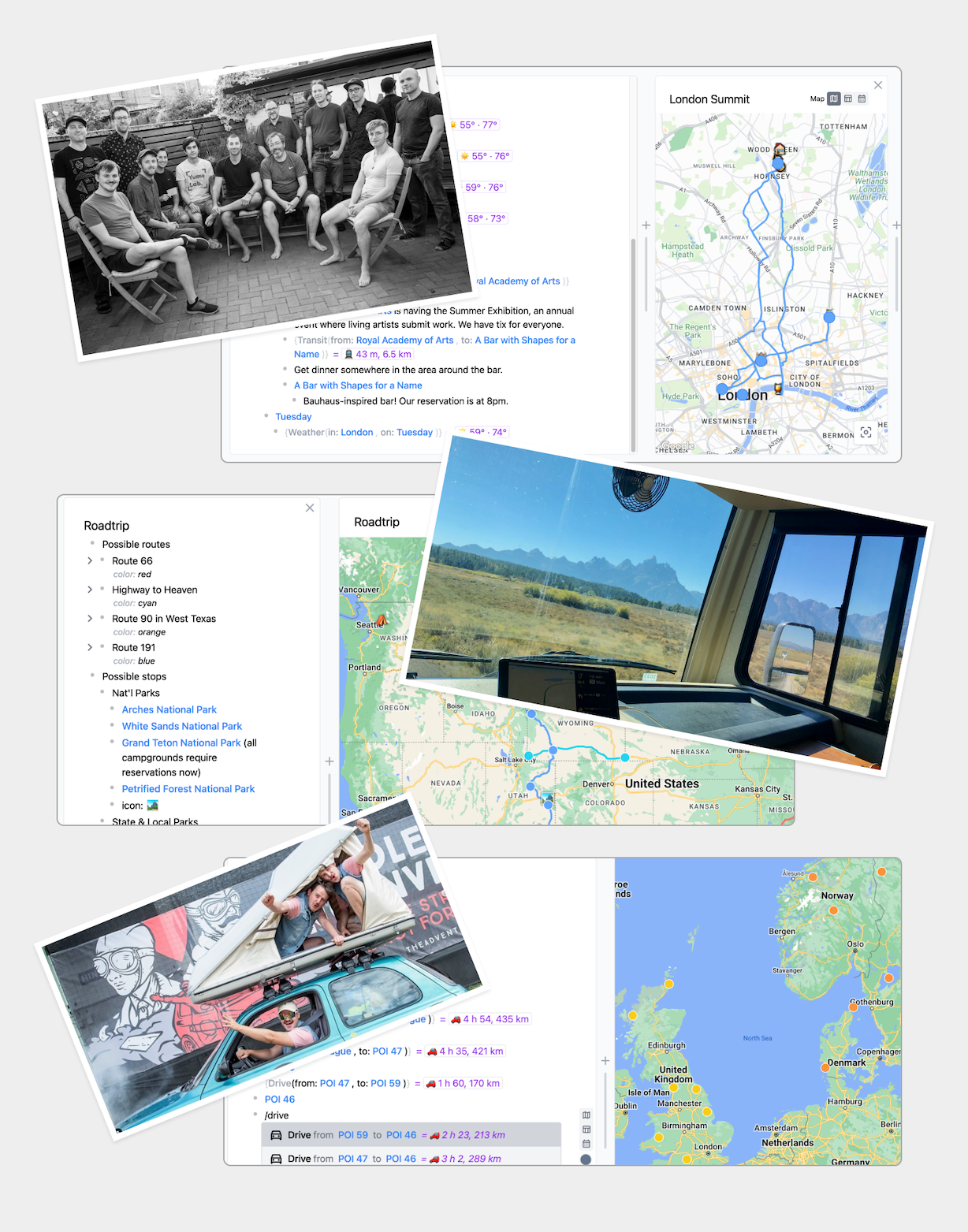
We used Embark to help plan a lab summit, a multi-month RV trek, an adventure trip around Europe, and more.
An RV journey: Alexander was planning a new round of full-time travel by RV where he cared not just about the destinations, but the routes chosen to get there. Embark could host wishlists of both routes and points of interest, in a list with contextual notes, and visualized on a map.
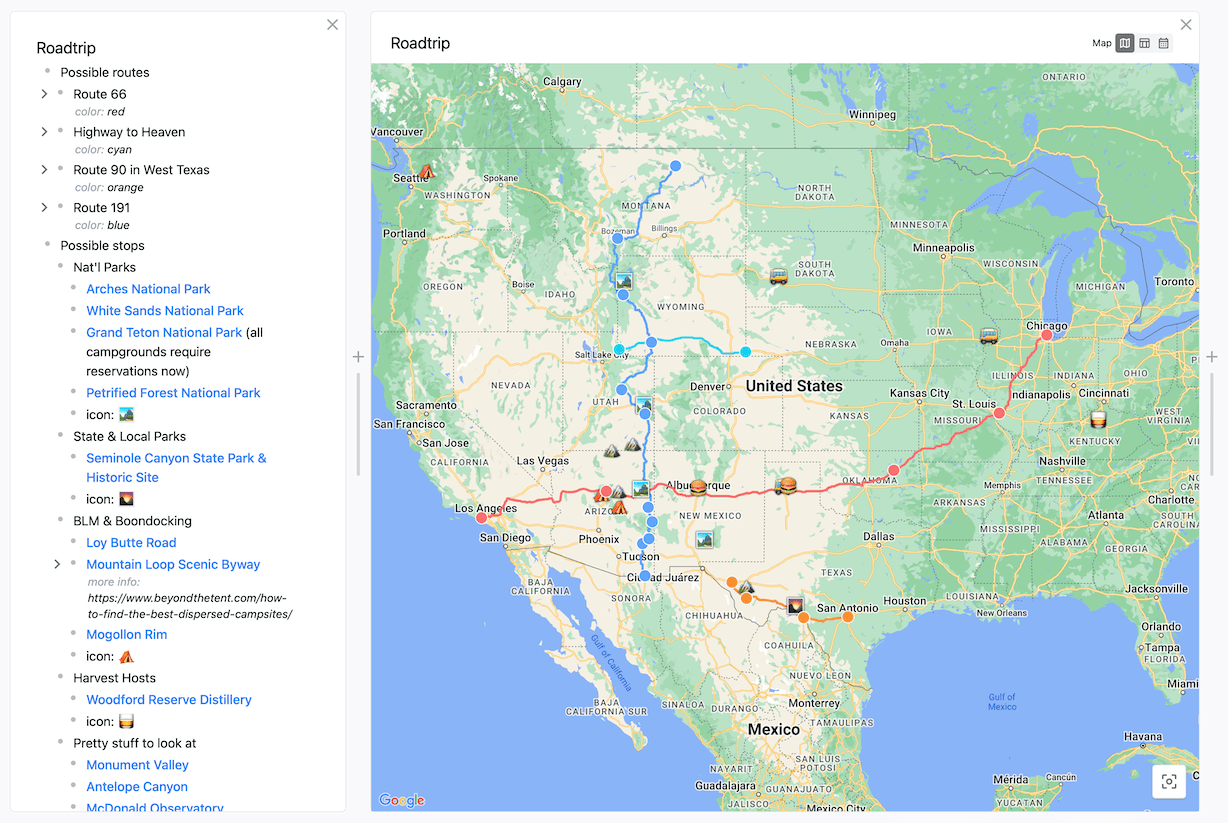
Mapping out a long RV journey across the United States
A dinner pit stop: Geoffrey was on a road trip to Maine and needed to decide where to stop for dinner. He used the outline view to assess relative drive times, and used the map view to pick a scenic coastal route.
Choosing between two dinner pit stop options, based on routing times
A lab summit: We used Embark to support us in planning a team gathering: recording the places we were staying, locations of activities, and planning daily schedules. It was helpful to interleave casual notes directly in the document with the rest of our plans. We believe this kind of complex group trip represents the kind of use case where a tool like Embark can ultimately be most helpful.
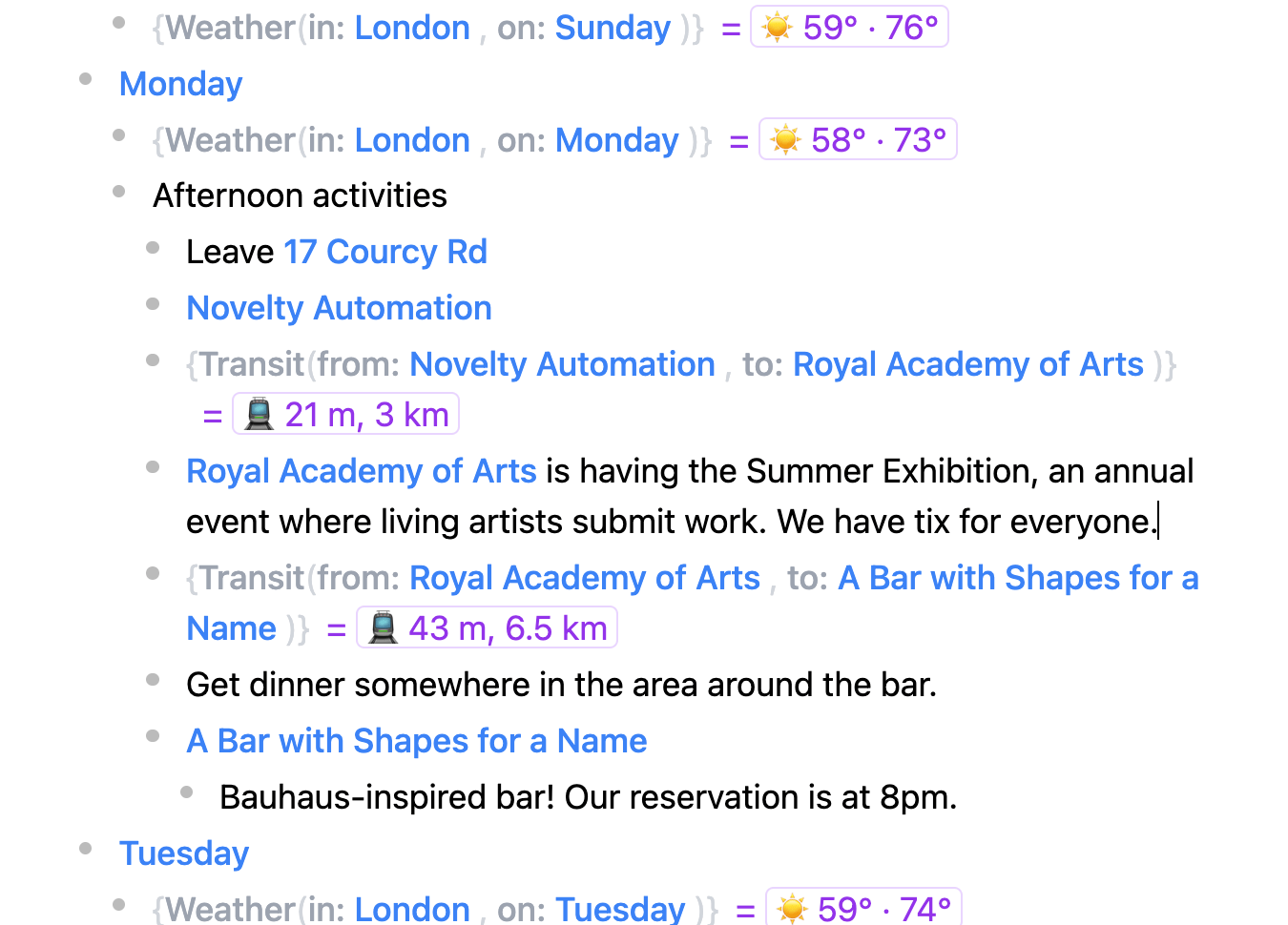
Planning activities and travel time for an afternoon of activites
An adventure journey: Paul used Embark to participate in an adventure rally called Poles of
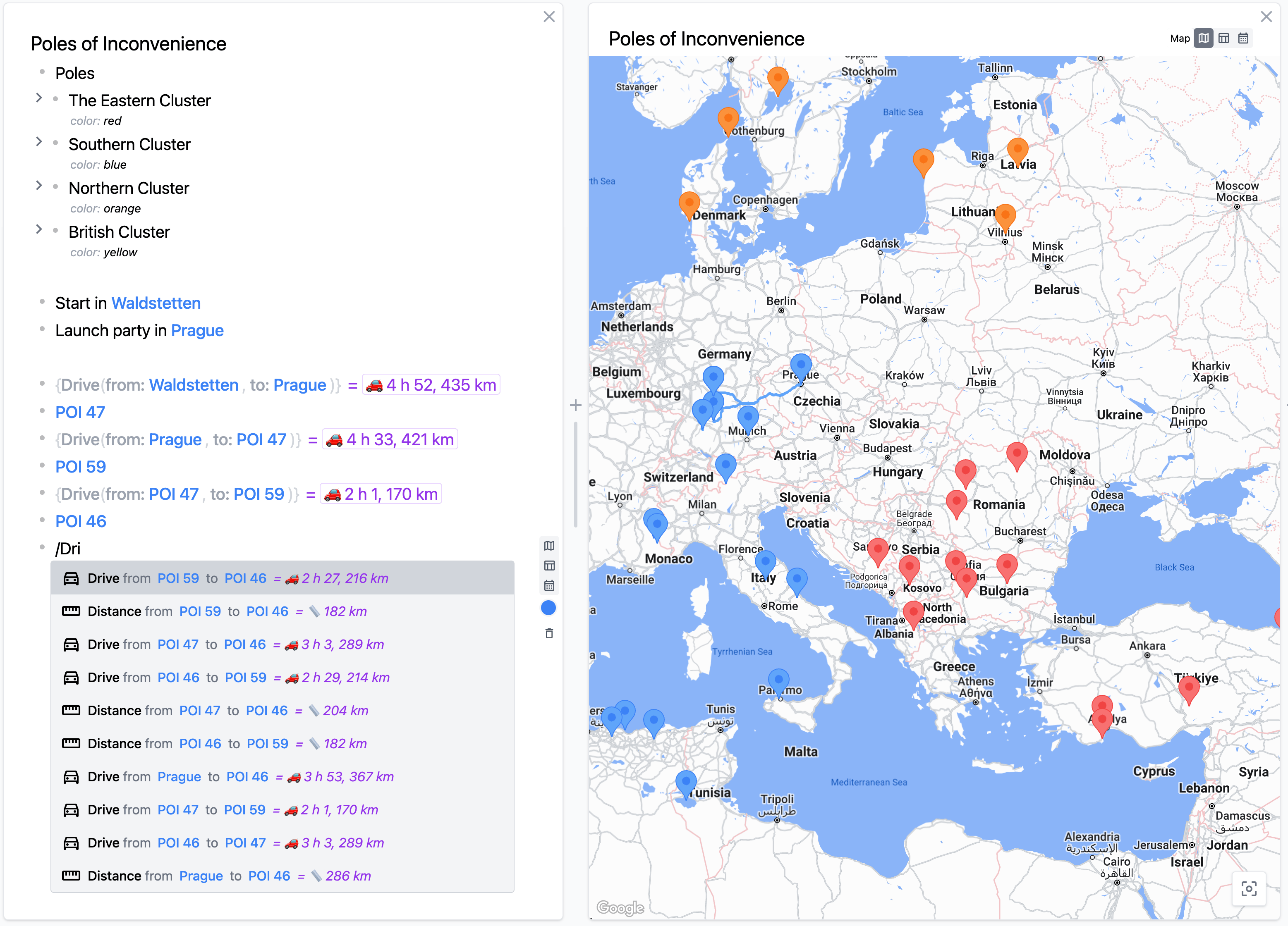
Mapping an adventure trip spanning across eastern Europe
Overall, across all these trips, we found Embark to be a valuable planning companion. Although we had many usability issues because Embark is a rapidly developed research prototype and not a polished product, we found that Embark helped us plan in unique ways that we have not found in other kinds of tools. Here are some reflections on the strengths and limitations of our prototype.
Freedom to annotate is valuable
People want to take notes on things. In the physical world, we write on sticky notes, magnetic whiteboards, or the margins of a book or paper.
In the digital realm, our modern systems fail to support this inclination. We find ourselves wanting to write in the margins of our digital things, but are unable to. Sometimes, a notes field is supported on certain data types by certain apps (for example, you can often take notes on calendar events or contacts). More often, we’re left to use a separate app solely dedicated to note-taking, or, of course, pencil and paper.
Embark redraws the boundaries of our digital things to make taking notes on and around them part of the basic computational medium. Instead of putting notes in a separate app, or as an attribute on certain types of things, Embark inverts the relationship: computations and views are embedded in the user’s note-taking environment.
At first, when starting with a blank document, Embark resembles a familiar note-taking app. Users can write stream-of-consciousness if they wish, bringing in computation and views as they go. Or, they can work primarily with functions and views, and add any notes next to or around their things as needed. Critically, these notes flow together with the functions, views, and things (e.g. places) they add context to.
We found that being able to freely write notes anywhere in our planning tool provided a graceful fallback for any situation: we could write down anything as text if a more ideal structured data format was not available. We frequently found ourselves mixing mentions and formulas together with freeform text notes and annotations to capture thoughts in the moment.
Documents capture thought process and context
In our early prototypes, we explored ways for GUI widgets to compose with one another. For example, we tried many variations of putting map and weather views side by side and having them share data with each other.
An early prototype of Embark which emphasized composition between GUI widgets
These prototypes seemed appealing in demos, but we found that in actual planning scenarios they had a key problem: they didn’t leave a durable trace of the entire planning thought process. We found ourselves often having a notes app open next to the planning tool, defeating much of the purpose.
In contrast, once we started hosting tools within an outline, we were able to use this outline as a shared record of the entire thought process. We have found that Embark documents naturally grow from the most primitive stage of a plan (“Maybe we should go on a trip to Miami?”) to the final detailed logistics, recording all the steps along the way and remaining useful at every stage of formality.
A document also serves as a natural hub for shared context. In app-centric computing, the information about a single trip tends to get spread across multiple apps: random emails, airline apps, Google Maps, etc. Bringing all the information for a trip into a single easily referenced doc is useful for humans since we can more easily find what we need. But it turns out having the context in one place is also useful for computers.
One example of the value of shared context is in Embark’s autocomplete feature. The user can type “Route from Home to Hotel” and get useful autosuggestions if they have already entered the address for their home and hotel into the document. We have been surprised by how magical this simple interaction feels. A straightforward fuzzy text search is powerful when given the right context.
Having all the context for a trip in one document could also help power even better autosuggestions in the future. For example, we could use AI models to interpret all the context in a document, and use that to suggest computations that you might want to run. AI tools often struggle to gather together all the context for a particular task, but having a document with all the relevant information already gathered eliminates that bottleneck.
Reifying computations enables composition
Most software entangles the abstract functionality of the application with the interface that presents it to the user. For example, in Google Maps, users can search for a route between two points, but neither the resulting route nor the process of computing that route can be separated from the visual interface.
As a result, many compositional tasks are needlessly cumbersome: the only way to compare two routes is to place two windows next to each other. Of course, a maps app could perhaps add a feature to view multiple routes together, but that would only solve this one specific problem. The user has no direct access to computations and their results.
In contrast, in Embark, computations and their results are more directly exposed, and are treated separately from views that visualize them. Formulas can be freely organized in an outline however the user prefers, enabling open-ended workflows: expressing a sequence of routes in a list, comparing possible alternatives, gathering routes in a shared view, chaining math computations, and more. We found that this flexibility enabled us to use the same formulas in very different ways across different trips.
Formulas share some challenges of command line or chat bot interfaces: it is important that users can easily discover commands and understand how to populate their arguments usefully. In our usage, these issues have not been problematic because our auto-suggestion mechanisms (both the buttons sidebar and fuzzy text autocomplete) usually make it easy to find the correct formula without writing it out manually. However, growing such a system to support more novice users and more kinds of functions would probably require further work on the user interface for formula entry.
Outlines balance flexibility and structure
Outlines strike a good balance between rigid structure and flexible ambiguity .
The parent-child hierarchy provides some minimal structure which enables many things in our model: grouping items, collapsing subtrees, enabling views for subtrees, referring to collections, and so on. These tasks would be more difficult in a more freeform medium like plaintext (as explored in our previous Potluck project) or a spatial canvas.
At the same time, the exact meaning of the outline hierarchy is left ambiguous: it can express containment, sequences, annotations, and more. The meaning is implied through the content. There is no fixed schema that you have to fit your thoughts into; you can start with a loose plan and gradually add more structure over time if desired.
Although the loose structure of Embark documents is an essential part of the informal experience for the user, it can be challenging to handle when performing computations on the data. When Embark tries to infer the meaning of the outline, it can never be sure what the user’s intention was: Should a list of places be interpreted as sequential steps in a route or as a set of alternatives?
Nonetheless, we have found these ambiguities can be usually managed with two approaches.
First, there many valuable things the computer can do without fully understanding all the implicit relationships in the user’s notes, especially since we have rich built-in structured data types for things like locations, dates, and functions. For example, if the user wants to see their travel plan on a map, it’s enough for Embark to visualize the location tokens in the notes without understanding how they are related.
Second, the system can be designed around the assumption that its inferences about user intent may be incorrect. As one example, this is why the system only suggests possible formulas that can be corrected by the user, rather than more assertively inserting formulas automatically.
One direction for further work might be to allow users to explicitly express more intent by distinguishing between different kinds of lists, such as unordered and ordered lists, or checkboxes to denote alternatives. Another approach would be to develop more powerful heuristics for inferring intent, either based on symbolic patterns matching patterns in the outline shape, or fuzzier approaches like using large language models to understand the natural language content of the document.
Limitations and future work
Extensibility: In our current prototype, we hardcoded a small number of formula functions like Route and Weather, as well as views like Map and Calendar, for ease of implementation. The fact that we were able to plan a broad variety of trips with just these few computational primitives demonstrates the flexibility of Embark’s compositional model.
Nevertheless, expanding Embark to a broader variety of use cases and domains would require growing the set of primitive functions and views available in the system. In the future, we envision tools like Embark as a deeply malleable system where views and formulas can be dynamically created from within the system itself. A first step could be allowing formula functions and views to be defined by writing JavaScript code within the system; further improvements might consider using end-user programming techniques to define these extensions without traditional coding.
Schemas and data interoperability: We decided to keep principled handling of data schemas out of scope for this project, so we handle schemas in a primitive way. For example, the map view looks for objects with a “location” property, and places imported from Google Maps have this property, but this schema is implicit and not enforced or described anywhere.
One of the main challenges with growing a tool like Embark further is finding ways for data representations from different tools to interoperate: both at a low-level—e.g. matching serialized representations of dates and GPS locations—but also in more conceptually tricky ways.
An intimate understanding of the data model is important to build computations in Embark. What fields do computations return? Which properties will the map interpret? For the developers of the system, this is second nature, but for new users to be successful these systems need much better wayfinding.
Collaboration: One intriguing benefit of the document metaphor is that it provides a natural locus for collaboration. A group can collectively plan and discuss a trip, all while pulling in dynamic information and computations. We chose not to focus on collaboration in this project, and we ran into prototype quality issues when trying to collaboratively edit Embark documents, so most of our usage ended up being relatively independent. In the future we’d like to further explore this thread, building on recent progress in maturing the Automerge local-first data stack.
Customizing views: We also think it would be worthwhile to further explore ways users could define how data flows into views. Given an existing calendar view, for example, a user could modify exactly what data is shown within the calendar by filtering, grouping, etc., such as to choose exactly what kinds of weather events are presented. This could become a simple means by which users can adapt rich, interactive views to more closely support their needs.
AI: Some preliminary experiments suggest Embark may be a promising medium for human-AI collaboration. An LLM-based assistant could receive a natural language request like “plan an itinerary for Saturday” and respond by adding content to an Embark document in the form of text, mentions, formulas, and/or views. This would provide a richer medium for collaborating on travel plans compared to a chatbot interface. We have also found that LLMs are capable of interpreting natural language context which is difficult for traditional code to understand—for example, “find a route from the airport to the conference” could infer which airport the user is referring to, and what the location of the conference is, based on the existing contents of the document.

Conclusion
Every day computers offer ever more powerful substitutes for traditional analog tools: calendars become dynamic, weather forecasts get regular updates, driving directions change with traffic predictions, and so forth. But these essential tools live in a restrictive environment dominated by siloed app architectures. Interfaces inside apps, and integrations between them, must be explicitly built by their developers in advance. This rigidity requires that users conform their thinking to match the interfaces on their screens, rather than allowing users to match tools to their specific tasks. Each new app demands understanding new interfaces, new constructs, and new behavior.
Personal software is home to so much of our lives: conversations with colleagues and loved ones, education in hobbies and careers, creation and exploration, entertainment, self-expression, and so on. We believe that rather than forcing people to adapt to rigid, one-size-fits-all interfaces, our software environments should adapt to each person’s needs, context, and mental models. With a proper set of new primitives, the digital realm could support more thoughtful engagement with the things that matter most to each of us.
Embark proposes an architectural change for the operating system: bringing data, computations, and views to people’s fingertips within a foundation of documents. Newly imported software would simply fold these new capabilities into users’ environments, with all of the existing affordances and interactions they already know. These ideas would apply to all kinds of domains, not just travel.
Today’s software is far from personal. Unbundling the app is just one important step; we must also invent new interactions around a new set of core primitives. Embark proposes one set of answers, but more importantly, it raises a line of questioning that deserves further exploration.
We welcome your feedback:
Thank you to Todd Matthews for the diagrams and photos in this essay; Alex Warth for developing the formal semantics in the appendix; John Underkoffler for early guidance; Peter van Hardenberg, James Lindenbaum, Mary Rose Cook, Ivy Reese, Jess Martin, Adam Wiggins, Taylor Rogalski, Josh Rozner, and the LIVE reviewers for feedback on this essay; Stian Håklev for information about Tana, and everyone at Ink & Switch for helpful feedback throughout.
Appendices
Appendix I: Concrete vs. abstract computations
There’s a key tension in Embark. On the one hand: we want to allow for abstract computations which repeat behaviors over sets of data. Computers are good at for loops, this saves the user time and effort and errors. On the other hand: we want to save the user from doing too much abstract reasoning. The user shouldn’t need to write complicated patterns that reason about huge classes of outline structures. We also don’t want the user to need to carefully put their outline in just the right shape for a computational pattern to match.
Spreadsheets address this tension with concrete computations plus smart copy-paste. Every cell refers to some specific set of inputs; you get abstraction with a convenient copy-paste tool for duplicating a computation in multiple places while fiddling with the inputs for each instance. But each instance is fundamentally concrete after the copy is done.
We take inspiration from this and do the same thing in Embark. Every computation operates on some specific concrete arguments which you can see, just like a spreadsheet formula operates on specific cells as inputs.
Filling in these concrete arguments every time can be tedious. To help out, Embark offers: 1) an autosuggest menu which guesses what formula you might want to insert at a particular point, 2) a repeat button which guesses how you might want to duplicate an existing computation. After autosuggest or repeat is done, every computation is specific and concrete.
This design is helpfully concrete. If the automation does the wrong thing, the user can just fix the arguments to a concrete formula instead of adjusting an abstract pattern or adapting the outline to follow a pattern. This follows our principle that Embark should never force the user to structure their outline in a certain way.
There are also drawbacks to this approach. The arguments are repeated for each formula which can be visually noisy. Another problem is that the arguments don’t update automatically; for example, if a user changes the date of a bullet in their trip plan, they need to update the corresponding date in all formulas below it manually.
However, these problems could be addressed with further one-off mechanisms, like a “staleness watcher” that attempts to heuristically detect formulas which have become out of date and need to be updated. In general, we believe that keeping formulas concrete and supplementing with one-off tools leads to a predictable user experience.
Appendix II: Formula language semantics
Embark uses a formula language that operates on an outline. In some ways, the language is similar to a common grid-based spreadsheet. Formulas are pure functions which can reference other cells, and updates propagate reactively through the outline. But Embark also has some differences from typical spreadsheets:
- An outline node can contain text with multiple formula expressions interpolated at various points.
- References to other nodes must handle the hierarchical outline structure, not a 2D grid.
- Inputs and outputs of formulas are sometimes outline nodes containing nested hierarchy, rather than scalar values or ranges on a grid of cells.
We have designed our language to handle these situations in a way that addresses many of the common scenarios we have encountered in travel planning. In this section we describe the a formal semantics for our language. This formal description does not exactly match our prototype implementation in all details, but it describes the essence of the language design.
Syntax
First, we describe a syntax for Embark. This syntax can be used to write down an unevaluated outline as a program.
(1) Nodes: An outline is constructed from nodes.
Each node contains:
- An internal system-managed ID, $id$
- An optional name, $n$
- Its main content: a list of terms, $\overline{t}$
- An ordered list of children, $\overline{N}$
Key-value properties on a node are represented using named children underneath the node.
(2) Terms: A term can be either a word $w$ or an expression in curly braces ${e}$. Because a node contains a list of terms, this means it can have a sentence of text with multiple expressions interpolated at various points.
(3) Expressions: An expression can be one of:
- A scalar value, $s$
- A mention of another node by ID, $@id$
- A relative reference to another node by name, $n$
- A function call with a list of expressions as arguments, $f(\overline{e})$
- A property name dereference on an expression, $e.n$
(4) Functions: All functions in the Embark language, e.g. Route and Weather, are hardcoded into the system and implemented in arbitrary JavaScript. This is much like a traditional spreadsheet language where it is not possible for the user to define new functions from within the system. Functions may perform I/O like accessing network APIs, but they must be side-effect-free with respect to the outline, and only return a value.
(5) Scalars: The primitive scalar values in the systems are numbers and strings.
Values
In an evaluated outline, all values are either scalar values or node values $NV$.
A node value is similar to the unevaluated node syntax defined above, except for two differences:
- The list of terms is evaluated to some value $v$
- Each of its children is evaluated to some value, so the list of children is a list of node values: $\overline{NV}$
The node table
The entire program is syntactically a single node, $N$. As a convenience in the formalism, we define the “node table” ($NT$) as a map from node id to the node’s abstract syntax.
The store
To help with evaluation, we also define a “value store” $\mu$ which maps node IDs to values.
To dereference the store ($\mu[id] = v$) we define two rules, a base case and recursive case:
Resolving relative references
Formulas can make relative refences to other nodes by name. For example, the formula route.distance * 0.35 is referencing a node named route. The value of this reference depends on the location of the node containing this formula.
The basic logic for looking up relative references is to look for a sibling node, parent node, or ancestor node with a matching name, in that priority order.
Formally, we can define a helper rule which says that the name n, used in a formula in node with id $id_{ctx}$ resolves to the node with id $id_{ref}$:
The rule’s definition has several cases:
Sibling: If one of the node’s sibling has the referenced name, the lookup resolves to that sibling. We allow references to siblings either before or after the node in the ordered list:
Parent: If a node’s parent has the name we want to lookup, then the name resolves to the parent:
Ancestor: If a name does not resolve to a sibling or parent, we recursively look upwards in the tree to ancestors:
Stratified writes into the store
Our big-step evaluation relation $e, id_{\text{ctx}}, \mu \Downarrow v $ requires a store of node values $\mu$. We “calculate” that store by evaluating the program’s expressions in a stratified way.
First, we define a helper which lets us access the first expression in a list of terms $\overline{t}$. This is going to be helpful because when a node contains text with interpolated expressions, it will evaluate to the value of the first expression.
Now we can define the stratified evaluation, which proceeds downwards in the tree:
To get the store for a program $N$, we can compute:
Evaluation
Now that we have a store of node values, we are ready to describe big-step operational semantics for an arbitrary expression $e$. We describes rules for evaluating each of the forms that an expression may take:
Scalar values simply evaluate to themselves:
Functions are evaluated by calling the function on the evaluated arguments:
Property access evaluates $e$ to a node value and finds the properly named child:
Name references uses the relative reference lookup logic above to dereference the name to a node and then evaluates that node:
Mentions use the ID of the mentioned node to and then evaluate to a node value:
Helper functions
For completeness, here are some helpers used in the evaluation semantics above.
evalExprs, which returns a list of values given a list of expressions:
get, which returns a value given a name to look up in a list of node values:
evalNodes, which evalutes a list of nodes to a list of node values: